| CPC G06Q 40/03 (2023.01) [G06F 40/289 (2020.01); G06F 40/58 (2020.01); G06N 20/00 (2019.01)] | 20 Claims |
|
1. A system for estimating creditworthiness, the system comprising:
one or more memories; and
one or more processors, communicatively coupled to the one or more memories, configured to:
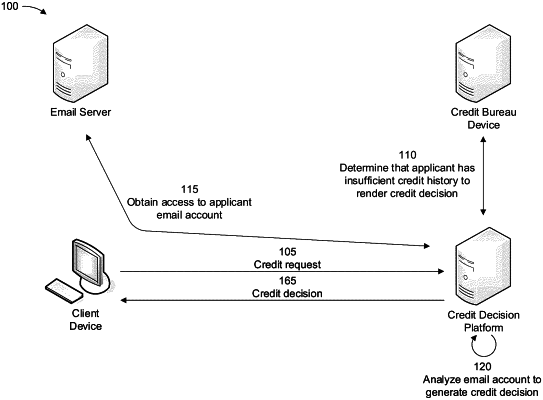
obtain access to an email account associated with an applicant based on the applicant having insufficient domestic historical data for a credit request of the applicant to be processed;
train a plurality of machine learning models to distinguish authentic email accounts from synthetic email accounts,
wherein a first machine learning model, of the plurality of machine learning models, is configured to use an input that includes a set of observations from historical data and generate an output that indicates whether the email account is authentic or synthetic using a target variable,
wherein the set of observations include a feature set which is extracted by a second machine learning model, of the plurality of machine learning models, from the historical data by performing natural language processing, and
wherein the plurality of machine learning models are trained to recognize patterns in the feature set that lead to a value of the target variable that determines whether the email is authentic or synthetic, and
wherein the patterns in the feature set include one or more of:
a pattern of received emails,
a pattern of email header information, a pattern of how email messages marked as spam are handled, or
a pattern relating to reading behavior;
identify, using the plurality of trained machine learning models, a set of email messages included in the email account that are relevant to the credit request from an email server,
wherein the set of email messages relevant to the credit request are identified, using the plurality of trained machine learning models, based on a determination that the email account is authentic;
analyze content included in the set of email messages using the plurality of trained machine learning models and the natural language processing to generate non-domestic historical data associated with the applicant;
determine a set of metrics that relate to an estimated creditworthiness of the applicant based on the non-domestic historical data associated with the applicant;
generate a decision that the credit request is granted based on the target variable indicating that emails in the set of email messages are authentic and the set of metrics that relate to the estimated creditworthiness of the applicant; and
provide information to allow the applicant to open a credit account based on the decision.
|