| CPC G06Q 30/0244 (2013.01) [G06Q 30/0255 (2013.01); G06Q 30/0275 (2013.01)] | 16 Claims |
|
1. A processor implemented method for training a budget constrained Deep Q-network (DQN) for dynamic campaign allocation in computational advertising, the method comprising:
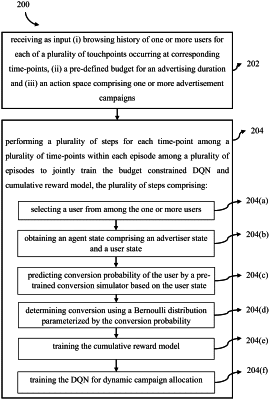
receiving as input, via one or more hardware processors, (i) browsing history of one or more users for each of a plurality of touchpoints occurring at corresponding time-points, (ii) a pre-defined budget for an advertising duration (T), and (iii) an action space comprising one or more advertisement campaigns, wherein the browsing history comprises an advertisement associated with a corresponding advertisement campaign from the action space, and a field set to one of ‘0’ indicating no-conversion of the advertisement and ‘1’ indicating conversion of the advertisement, at a corresponding touchpoint from among the plurality of touchpoints;
performing, via the one or more hardware processors, a plurality of steps for each time-point among a plurality of time-points within each episode among a plurality of episodes to jointly train a budget constrained DQN and a cumulative reward model, wherein the DQN is represented by an agent state, an action corresponding to the agent state and weights of the DQN and wherein the cumulative reward model is represented by the agent state, the action corresponding to the agent state and weights of the cumulative reward model, the plurality of steps comprising:
selecting (204(a)) a user from among the one or more users, wherein the browsing history of the user for touchpoint corresponding to the time-point is comprised in the received input;
obtaining (204(b)) the agent state comprising an advertiser state and a user state, wherein the advertiser state comprises a budget of advertisement available at the time-point and number of conversions occurred till the time-point, and wherein the user state is derived from a pre-trained autoencoder based on the browsing history of the user for the touchpoint corresponding to the time-point;
predicting (204(c)) conversion probability of the user by a pre-trained conversion simulator based on the user state, wherein the pre-trained conversion simulator is a Long Short Term Memory (LSTM) based Encoder-Decoder model trained using the user state and a cross-entropy loss function;
determining (204(d)) conversion using a Bernoulli distribution parameterized by the conversion probability, wherein the determined conversion is an immediate reward corresponding to the agent state;
training (204(e)) the cumulative reward model by:
assigning cumulative sum of all the immediate rewards determined in an episode among a plurality of episodes to all pairs of agent state and the action that occur in the episode, wherein the action corresponding to the agent state is determined by the DQN;
storing maximum cumulative rewards across all the plurality of episodes for all the agent state-action pairs in a dictionary;
storing all the agent state, action, and maximum cumulative reward tuples in a first replay buffer; and
updating the weights of the cumulative reward model based on a loss function which minimizes squared error between (i) maximum reward across all the plurality of episodes obtained from the first replay buffer and (ii) maximum reward predicted by the cumulative reward model for the agent state, wherein the cumulative reward model employs three layers of Rectified Linear Unit (ReLU) multi-layer perceptron (MLP) parameterized by the weights and wherein the cumulative reward model is trained to reward the conversions;
training (204(f)) the DQN for dynamic campaign allocation by:
determining the action from the action space based on the agent state using an epsilon greedy policy;
obtaining a cumulative reward corresponding to the determined action using the cumulative reward model;
determining updated agent state corresponding to the user at a successive time-point from among the plurality of time-points using a state transition routine, wherein the state transition routine comprises:
deriving user state of the user from the pre-trained autoencoder based on browsing history of the user for the touchpoint corresponding to the time-point and action determined by the DQN;
predicting conversion probability of the user by the pre-trained conversion simulator based on the user state at the time-point and action determined by the DQN;
determining conversion using the Bernoulli distribution parameterized by the conversion probability;
calculating a bid-price corresponding to the action determined by the DQN using an offline bidding process by an advertiser;
computing budget left at the successive time-point and number of conversions at the successive time-point by subtracting the calculated bid-price from budget left at the time-point and adding the determined conversion to number of conversions at the current time-point; and
determining the agent state at the successive time-point as a combination of the user state, budget left at the successive time-point and number of conversions at the successive time-point;
storing a tuple comprising agent state corresponding to the user, action, cumulative reward, and updated agent state corresponding to the user in a second replay buffer; and
updating the weights of the DQN using Bellman rule based on a tuple sampled from the second replay buffer, wherein the DQN employs two layers of Rectified Linear Unit Multi-Layer Perceptron (ReLU MLP) followed by a fully connected layer and wherein the DQN is trained to determine an optimal campaign allocation policy with a fixed budget for the advertising duration, and wherein the trained DQN and the trained cumulative reward model resulting after the plurality of episodes are used to allocate dynamic campaigns to online users during an advertising duration.
|