| CPC G06N 7/01 (2023.01) [G06F 16/248 (2019.01); G06F 16/2462 (2019.01); G06F 16/285 (2019.01)] | 18 Claims |
|
1. A method comprising:
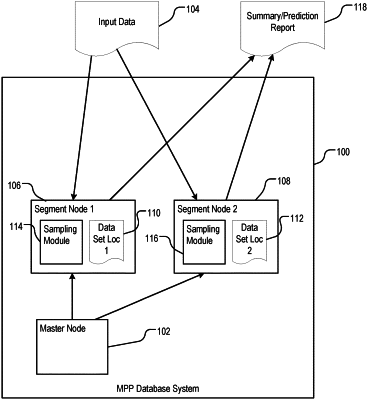
receiving, by a master node of a distributed computing system, input data including a result field storing values of a response variable and a plurality of data fields each storing values of a respective explanatory variable affecting the response variable of the result field;
determining, by the master node, a grouping variable as at least a portion of a distribution key for distributing a respective portion of the input data to each of a plurality of segment nodes of the distributed computing system, each segment node of the plurality of segment nodes including one or more computer processors;
distributing, by the master node, the respective portion of the input data to each of the plurality of segment nodes according to the distribution key, wherein each respective portion of the input data corresponds to a respective different value or set of values that the grouping variable can take;
generating, by each segment node of the plurality of segment nodes and in parallel among the plurality of segment nodes, a plurality of samples of a posterior distribution of the input data using the portion of the input data distributed to the segment node, the posterior distribution being conditioned on the grouping variable having the value or set of values corresponding to the portion of the input data distributed to the segment node;
determining, using all of the pluralities of samples generated by all of the plurality of segment nodes, a set of prior regression coefficients that identify a respective effect of each explanatory variable on the response variable given any value for the grouping variable;
determining, by each segment node of the plurality of segment nodes and in parallel among the plurality of segment nodes, a respective set of posterior regression coefficients using (i) the plurality of samples generated by the segment node and (ii) the set of prior regression coefficients, the respective set of posterior regression coefficients identifying a respective effect of each explanatory variable on the response variable, given that the grouping variable has the value or set of values corresponding to the portion of the input data distributed to the segment node;
obtaining a new sample identifying (i) a respective value for each explanatory variable and (ii) a particular value for the grouping variable; and
processing the new sample using the set of posterior regression coefficients corresponding to the particular value for the grouping variable to generate a predicted value for the response variable, given that the grouping variable has the particular value.
|