| CPC G06F 40/186 (2020.01) [G06F 18/2411 (2023.01); G06F 40/109 (2020.01); G06F 40/30 (2020.01); G06N 20/00 (2019.01)] | 18 Claims |
|
1. A computer-implemented method comprising:
obtaining a user-selected input image including contents of different content types;
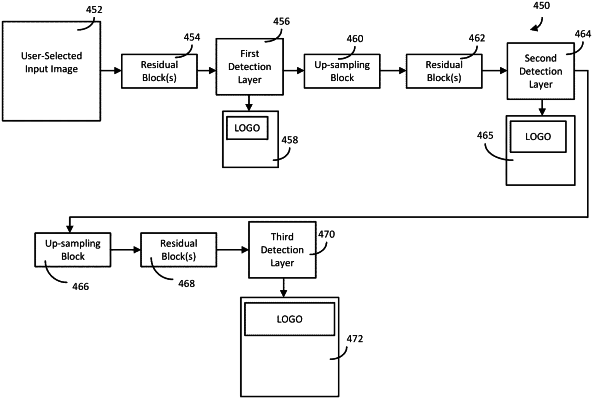
extracting characteristics associated with the user-selected input image using one or more machine learning models, wherein the characteristics comprise: 1) layout information indicating a position and a content type of each of the contents within the user-selected input image; and 2) text attributes indicating at least a font of text of each textual element included in the user-selected input image, wherein the text attributes are identified by processing a plurality of textual elements identified in the layout information concurrently, and wherein extraction of the text attributes comprises cropping out regions of textual elements and superimposing each region of textual elements on a plain background; and
generating a template including editable regions at positions corresponding to the contents of the user-selected input image, the editable regions including editable text regions that are each tagged with the text attributes of the corresponding textual element of the user-selected input image, wherein the template provides a baseline to generate a final image that emulates the characteristics associated with the user-selected input image.
|