| CPC H04W 24/02 (2013.01) [H04L 25/0254 (2013.01); H04L 41/16 (2013.01)] | 8 Claims |
|
1. A low-power wide-area network integrated sensing and communications method based on channel sensing and reinforcement learning, comprising:
receiving, by an LPWAN (low-power wide-area network) gateway receiver, an uplink signal transmitted by a terminal node, and demodulating the uplink signal by using a soft demodulation algorithm, wherein for a demodulation result, under a model of an additive white Gaussian noise channel, a noise follows Gaussian distribution with zero mean N(0, σ2), and based on a maximum a posteriori criterion, there is a conditional probability P(Y|XAω):
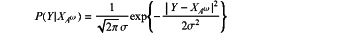 where Y denotes an actual signal received by the receiver, and XAω denotes a modulated signal of the symbol Aω∈Ω;
determining a bit log-likelihood ratio calculated according to the uplink signal by a Bayes formula
 wherein transmission probabilities p(x) of symbols are equal, formula so that the bit log-likelihood ratio of the kth bit is as follows:
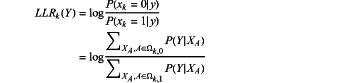 where Ωk,0, Ωk,1 denotes sets of symbols with the kth bit equal to 0 and 1, respectively, and Ω={A1, A2, . . . , AW} denotes a set of all possible symbols received;
thereby obtaining a set of bit log-likelihood ratios and realizing sensing of a wireless channel;
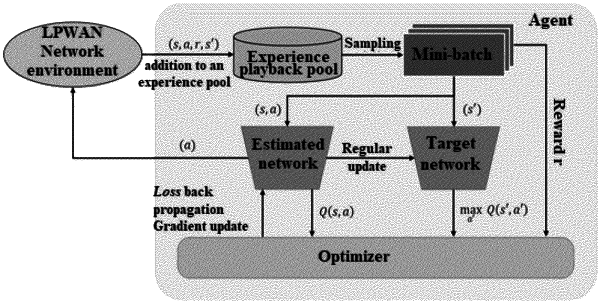
selecting, by a deep reinforcement learning model, key frequency points as pilot frequencies according to the bit log-likelihood ratio;
performing a channel estimation of the key frequency points based on the pilot frequencies according to a modulated channel model to obtain estimated channels of the key frequency points;
performing an original estimation of a complete channel according to the estimated channels of the key frequency points by an interpolation method to obtain an original estimated channel; and
performing N iterative estimations on the original estimated channel through N symbols acquired in a continuous time slice window, and completing reconstruction of a complete channel of a corresponding link during communication to obtain a reconstructed channel;
calculating a current optimal network configuration according to the reconstructed channel so as to allocate the current optimal network configuration to terminal nodes during the next downlink transmission;
before actual communication, performing offline training on the deep reinforcement learning model by using the following reward function (1), so that the model is used for the first round of communication during actual communication:
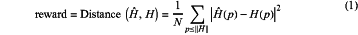 during the actual communication, performing online reinforcement learning training by using the following reward function (2), so that dynamically adaptive overall optimal communication transmission in a local LPWAN network is finally realized through continuous iterations:
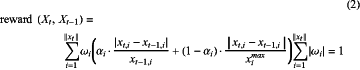 where Ĥ denotes a reconstructed channel, H denotes a real channel generated by simulation in the dataset, p denotes a frequency point position, ∥H∥=N denotes a total number of frequency points, Ĥ(p) denotes the reconstructed channel corresponding to the frequency point p, H(p) denotes the real channel corresponding to the frequency point p, Xt−1 denotes communication performance parameters for the previous round t−1, Xt denotes communication performance parameters for the current round t, and Xt=(xt,i), 0≤i≤∥X∥, ωi, and αi are all weight coefficients.
|