| CPC G10L 15/197 (2013.01) | 20 Claims |
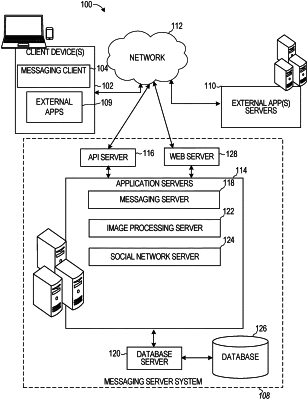
|
1. A method comprising: accessing, by one or more processors of an automatic speech recognition (ASR) engine, a language model (LM) that includes a plurality of n-grams, each of the plurality of n-grams comprising a respective sequence of words and a corresponding LM score, the ASR engine comprising an acoustic component and a decoder;
converting, by the acoustic component, voice input into logits of inferred characters of phonemes; receiving a list of words associated with a group classification, each word in the list of words being associated with a respective weight;
computing, based on each of the corresponding LM scores of the plurality of n-grams, a probability that a given word in the list of words associated with the group classification appears in an n-gram in the LM comprising an individual sequence of words;
identifying an individual portion of words in the list of words that is excluded from a subset of n-grams comprising the individual sequence of words;
combining each word in the individual portion of words with the individual sequence of words to generate one or more new n-grams to add to the subset of n-grams to form an updated subset of n-grams;
distributing an average of probabilities computed using sums of probabilities of different words in the list of words and the individual sequence of words across n-grams in the updated subset of n-grams to associate each n-gram in the updated subset of n-grams with a particular LM score;
adding the updated subset of n-grams comprising the one or more new n-grams to the LM;
processing, by the decoder, the logits of inferred characters of phonemes using the LM comprising the one or more new n-grams; and
generating a transcript of the voice input based on the logits of the inferred characters of the phonemes that have been processed using the LM.
|