| CPC G06V 10/774 (2022.01) [G06V 10/22 (2022.01); G06V 10/267 (2022.01); G06V 10/776 (2022.01); G06V 10/82 (2022.01); G06V 10/945 (2022.01); G06V 10/98 (2022.01); G06V 20/40 (2022.01)] | 9 Claims |
|
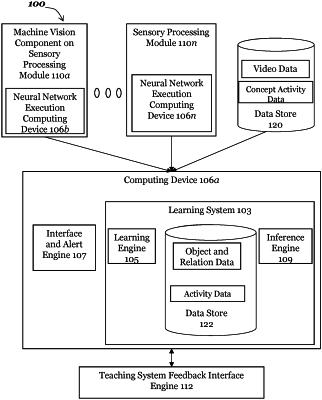
1. A method for training a self-directed, dynamic learning system to identify components of time-based data streams, the method comprising:
processing, by a machine vision component executing on a first computing device and in communication with a self-directed, dynamic learning system executing on a second computing device, a video file to detect at least one object in the video file;
displaying, by the self-directed, dynamic learning system, the processed video file, wherein displaying further comprises generating a user interface including a display of at least a portion of the processed video file and an identification of the detected at least one object, wherein displaying further comprises segmenting at least one image of the video file into at least one region;
receiving, by the self-directed, dynamic learning system, user input including an identification of an unidentified object in the processed video file displayed by the learning system;
processing, by a learning engine of the self-directed, dynamic learning system, the at least one region;
generating, by the self-directed, dynamic learning system, a proposed identification of at least one potential object within the at least one region;
displaying, by the self-directed, dynamic learning system, the at least one region and the at least one potential object; and
receiving, by the self-directed, dynamic learning system, user input accepting the proposed identification.
|