| CPC G06V 10/774 (2022.01) [G06T 7/11 (2017.01); G06V 20/56 (2022.01); G06T 2207/20028 (2013.01); G06T 2207/20081 (2013.01)] | 7 Claims |
|
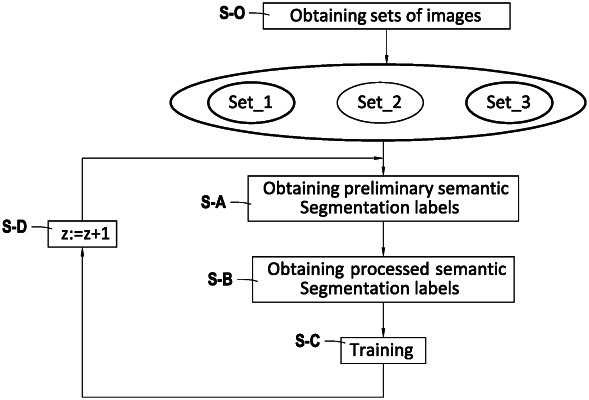
1. A method for training a model to be used for semantic segmentation of images taken under low visibility conditions, comprising:
obtaining a plurality of sets of images, each set of images being associated with an index z comprised between 1 and Z, the index z indicating a level of visibility of the images of the set of images, 1 corresponding to the highest level of visibility and Z corresponding to the lowest level of visibility,
wherein the model is initially trained to perform semantic segmentation using an annotated set of images having a level of visibility of 1 and the associated semantic segmentation labels, and
for z being greater than or equal to 2, iteratively training the model comprising:
a—obtaining, for at least a first image of the set of images of index z, a preliminary semantic segmentation label by applying the model trained on the set of images of index z−1 to the first image,
b—obtaining, for the at least the first image, a processed preliminary semantic segmentation label using the preliminary semantic segmentation label and a semantic segmentation label obtained by applying the initially trained model on a selected image of the set of images of index 1, the selected image being selected as the image having a camera view which is closest to a camera view of the first image by:
using a cross bilateral filter between the semantic segmentation label associated with the selected image of the set of images of index 1 and the semantic segmentation label associated with the first image, and
performing a fusion of an output of the cross bilateral filter with the semantic segmentation label associated with the first image,
wherein the cross bilateral filter performs:
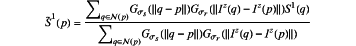 in which:
p and q are pixel positions,
Ŝ1(p) is the output of the cross bilateral filter for a pixel p,
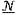 (p) is a neighborhood of p, (p) is a neighborhood of p, Gσs is a spatial-domain Gaussian kernel,
Gσr is a color-domain kernel,
Iz(q) and Iz(p) respectively designate a color value at pixel q and pixel p in the first image from the set of index z, and
S1(q) is a semantic segmentation label at pixel q for the selected image of the set of images of index 1,
c—training the model using:
the set of images of index z and the associated processed semantic segmentation labels, and
a synthetic set of images of index z and the associated semantic segmentation labels both generated from the annotated set of images having a level of visibility of 1 and the associated semantic segmentation labels; and
d—performing steps a to c for z+1.
|