| CPC G06V 10/764 (2022.01) [G06V 10/454 (2022.01); G06V 10/82 (2022.01)] | 15 Claims |
|
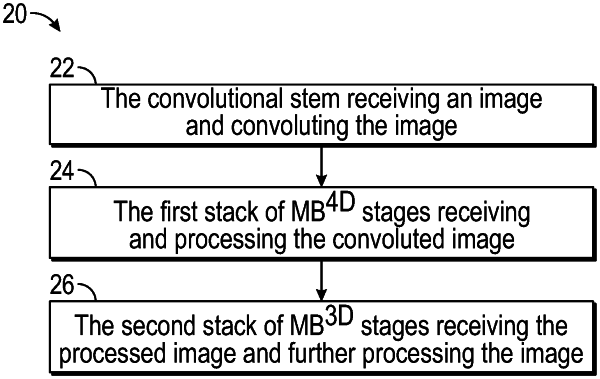
7. A method of using a vision transformer, comprising:
receiving and convoluting an image using a convolution stem to patch embed the image;
receiving and processing the patch embedded image using a first stack of stages stages including at least two stages of 4-Dimension metablocks (MBs) (MB4D); and
receiving the processed image from the first stack of stages and further processing the processed image using a second stack of stages including 3-Dimension MBs (MB3D), wherein each of the MB4D stages and each of the MB3D stages include different layer configurations, wherein each of the MB4D stages and each of the MB3D stages include a token mixer, and wherein each of the MB4D stages and each of the MB3D stages include pooling and multi-head self-attention, arranged in a dimension-consistent manner.
|