| CPC G06T 15/00 (2013.01) [G06T 5/50 (2013.01); G06T 11/00 (2013.01); H04N 19/46 (2014.11)] | 17 Claims |
|
1. A computer-implemented method for efficient dynamic video rendering comprising:
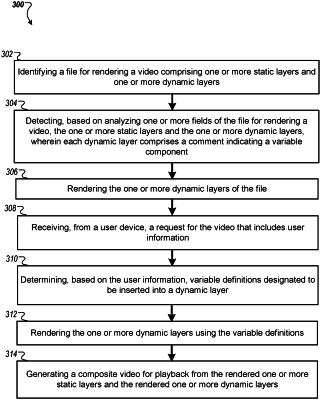
identifying a file for rendering a video comprising one or more static layers and one or more dynamic layers, wherein each dynamic layer comprises a variable component to be populated or altered prior to final rendering;
detecting, based on analyzing one or more fields of the file for rendering a video, the one or more static layers and the one or more dynamic layers, wherein each dynamic layer comprises a comment in a comment field for the dynamic layer that indicates a variable component, wherein the comment is provided in the comment field by a user, and wherein the detecting comprises detecting that a particular layer of the file is a dynamic layer based on a comment in the comment field for the particular layer;
rendering the one or more static layers of the file, the rendering comprising saving the static layers as images;
for each dynamic layer, saving instruction data that indicates the structure of the dynamic layer in a respective position with the static layers;
generating, based on the rendered one or more static layers and the instruction data for each dynamic layer, a template that represents the one or more static layers and the one or more dynamic layers;
after rendering the one or more static layers, receiving, from multiple user devices, respective requests for the video, wherein each request includes contextual data that characterizes an environment in which the video will be displayed at the user device from which the request was received, the contextual data comprising user information for a user of the user device from which the request was received and device information about the user device from which the request was received;
for each request:
for each dynamic layer, determining, based on the contextual data of the request and variable definitions comprising instructions for replacing or altering the variable component of the dynamic layer based on the contextual data of the request, an image for replacing the variable component or an alteration of the image;
rendering the one or more dynamic layers by populating the template using the variable definitions and the determined image or alteration to the image for each dynamic layer; and
generating a composite video for playback from the rendered one or more static layers and the rendered one or more dynamic layers, including, for each frame of the video, compositing rendered images of each layer of the frame, wherein the composite video for each request differs from the composite video for each other request.
|