| CPC G06F 9/4881 (2013.01) [G06F 9/30036 (2013.01); G06F 9/3836 (2013.01); G06F 9/3851 (2013.01); G06F 9/3877 (2013.01); G06F 18/214 (2023.01); G06N 20/00 (2019.01); H04L 9/0643 (2013.01)] | 15 Claims |
|
1. A computer-implemented method comprising:
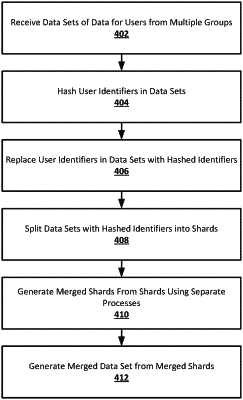
receiving two or more data sets of data for users wherein each of the two or more data sets belongs to a separate one of two or more groups;
hashing user identifiers in the two or more data sets to generate hashed identifiers for the two or more data sets;
replacing the user identifiers in the two or more data sets with the hashed identifiers;
splitting each of the two or more data sets to generate shards, wherein each of the two or more data sets is split into the same number of shards by splitting each of the two more data sets such that the hashed identifiers that are common to two or more of the two or more data sets are in equivalent shards from the two or more of the two or more data sets;
generating merged shards by merging the shards using a separate running process for each of the merged shards, wherein each of the merged shards is generated using shards from more than one of the two or more data sets;
performing an operation on all of the merged shards wherein performing an operation on all of the merged shards comprises joining the merged shards into a merged data set; and
training a machine learning system using the merged data set.
|