| CPC G06F 3/167 (2013.01) [G06F 3/04817 (2013.01); G06F 3/04842 (2013.01); G10L 15/1815 (2013.01); G10L 15/1822 (2013.01); G10L 15/22 (2013.01); G10L 2015/223 (2013.01); G10L 2015/225 (2013.01)] | 21 Claims |
|
1. A method, comprising:
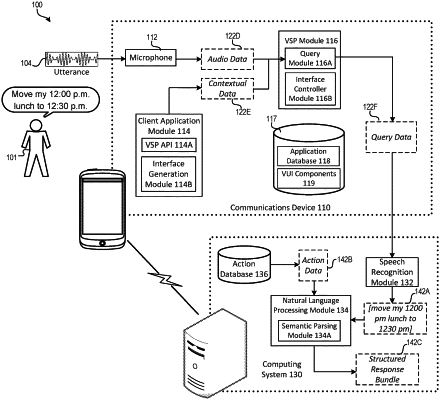
obtaining, by a voice service provider executing in part on a user device and in part on a server, audio data that is captured by at least one microphone of the user device and that captures a spoken utterance of a user of the user device;
obtaining, by the voice service provider, contextual data that characterizes a current interaction between the user and a particular application executing at the user device, and that identifies a version of the particular application;
identifying, by the voice service provider and based on performing speech recognition, linguistic elements, the linguistic elements including words that represent the spoken utterance captured by the audio data and that are relevant to the contextual data;
determining, by the voice service provider, that the spoken utterance is directed to the particular application based on the linguistic elements being consistent with the particular application and the interaction;
identifying, by the voice service provider and based on the version of the particular application, a structured format of application-specific commands and data inputs for the version of the particular application;
performing, by the voice service provider, natural language processing based on the identified linguistic elements, including the words, and based on action data, correlated with the linguistic elements and the contextual data;
determining, based on performing the natural language processing, an application-specific meaning of the spoken utterance, the application-specific meaning being associated with the particular application;
generating, by the voice service provider, based on performing the natural language processing, based on the application-specific meaning, based on the structured format, and based on the action data, structured data that includes one or more of the application-specific commands and one or more of the data inputs for the version of the particular application; and
transmitting, by the voice service provider and to the particular application executing at the user device, the structured data, wherein transmitting the structured data to the particular application causes the particular application to perform one or more application-specific actions, of the particular application, in accordance with the structured data.
|