| CPC G06F 16/906 (2019.01) [G06F 16/75 (2019.01); H04N 21/4332 (2013.01); H04N 21/4532 (2013.01)] | 20 Claims |
|
1. A computer-implemented method for clustering a plurality of content items of a data set, comprising:
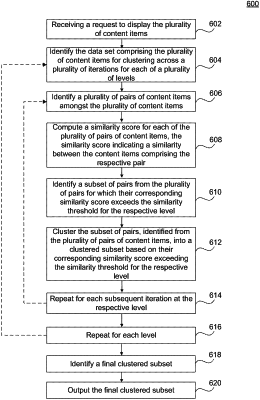
receiving, by at least one computer processor, a request to display the plurality of content items;
identifying the data set comprising the plurality of content items for clustering across a plurality of iterations for each of one or more levels, each level of clustering comprising a different similarity threshold;
performing for each of the one or more levels:
computing a similarity score for each of a plurality of pairs of content items;
identifying a subset of pairs from the plurality of pairs, wherein the similarity score, for each pair from the subset of pairs, exceeds a similarity threshold for a respective level;
clustering the subset of pairs, for each pair from the subset of pairs that exceed the similarity threshold for the respective level, into a clustered subset based on the similarity score; and
repeating the computing the similarity score, the identifying the subset, and the clustering the subset for each of the plurality of iterations for the respective level, for each subsequent iteration at the respective level;
identifying a final clustered subset comprising the clustered subset after each of the plurality of iterations for each of the one or more levels after the performing has been completed; and
outputting the final clustered subset for display, responsive to the request to display the plurality of content items.
|