| CPC G06F 16/2365 (2019.01) [G06F 16/215 (2019.01); G06F 16/285 (2019.01); G06F 40/169 (2020.01); G06F 40/295 (2020.01); G06F 40/30 (2020.01); G06N 5/04 (2013.01); G06N 20/00 (2019.01); G06Q 10/0635 (2013.01); G06Q 50/18 (2013.01); G06Q 30/018 (2013.01)] | 23 Claims |
|
1. A computer-implemented system for providing integrity due diligence on behalf of a company seeking to create a business relationship with a potential third-party product or service provider, comprising:
a memory for storing and managing data;
a user interface that electronically receives user input; and
a processor coupled to the memory and the user interface, the processor configured to determine an adverse media risk score associated with the potential third-party product or service provider based on negative sentiment from a plurality of news feed articles, the determination of the adverse media risk score comprising:
creating at least one news article source list for the third-party entity;
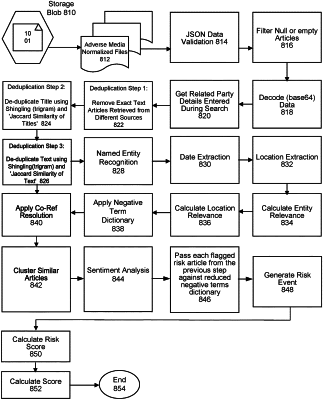
triggering, for each of the at least one news article source list, a data extraction function to form a news article corpus based on each of the at least one source list, the data extraction function comprising:
executing an automated data extraction through scraping of website content in a plurality of different data types from one or more websites for each news article source list;
parsing the extracted data into a common data type; and
normalizing the parsed data from a raw format into a common format grouped by a plurality of data categories;
performing a de-duplication of each news article from the news article corpus based on a similarity index, wherein the de-duplication process is based on one or more of exact title, similar title and similar content;
extracting one or more relevant texts from the news article corpus, the extraction comprising:
creating a negative terms dictionary;
applying the negative terms dictionary to the news article corpus to find matches between words in the negative terms dictionary and in the news article corpus wherein a minimum number of matches is required for text to be considered relevant text;
applying an organization filter to the news article corpus comprising (1) normalizing the potential third-party product or service provider name against a set of keywords and (2) counting the number of occurrences of the normalized third-party product or service provider name within each document in the news article corpus, wherein a minimum number of occurrences is required for text to be considered relevant text from a document within the news article corpus;
applying a character count filter to the news article corpus comprising (1) determining a mean number of article characters for the news article corpus and (2) discarding any article from the news article corpus that has a character count that is over two standard deviations away from the mean; and
applying weights to each document in the news article corpus by determining a proximity of words in the negative terms dictionary to the normalized third-party product or service provider name;
clustering a set of news articles corresponding to a potential risk event such that only one potential risk event may be identified from the set of news articles, wherein the clustering is achieved by density based spatial clustering of application with noise to identify similar type of events within a given time frame;
performing a classification of sentences to determine a sentiment score;
identifying a risk event, wherein the risk event comprises one or more of: litigation, sanctions, adverse media, background and key individuals;
calculating a risk score for each risk event based on an entity relevance, a section relevance, and a risk relevance; and
based on the risk score, generating, via the user interface, an output wherein the output comprises a graphic that illustrates each risk event and supporting articles generated via machine learning algorithm that identifies negative content.
|