| CPC G06F 16/215 (2019.01) [G06F 16/2228 (2019.01); G06F 16/285 (2019.01)] | 19 Claims |
|
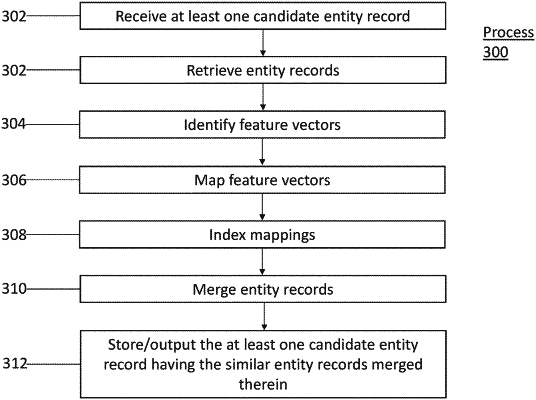
1. A computer-implemented method comprising:
receiving, by at least one processor, a plurality of data items associated with a plurality of entity records corresponding to at least one candidate entity record, the at least one candidate entity record being associated with at least one classification;
wherein the plurality of data items associated with the plurality of entity records comprise:
i) a quantity data item representing a quantity associated with an attribute of each entity record;
ii) an entity name data item representing an attribute as a name associated with each entity record;
iii) an entity address data item representing an attribute such as an address associated with each entity record;
iv) a second set of data items representing at least one attribute associated with the at least one candidate entity record, wherein the second set of data items comprises a merged set of the plurality of data items;
generating, by the at least one processor, a set of entity feature vectors associated with the plurality of entity records based at least in part on the plurality of data items;
identifying, by the at least one processor, at least one group of data item feature vectors associated with the plurality of data items;
utilizing, by the at least one processor, at least one machine learning model to map the plurality of entity records to clusters based on the set of entity feature vectors, the feature vectors pertaining to the at least one group of data item feature vectors associated with the plurality of data items and the at least one set of candidate entity feature vectors;
merging, by the at least one processor, a set of high similarity entity records based on the entity records exceeding a similarity threshold applied to the clusters;
utilizing, by the at least one processor, an ingestion module to automatically index clusters of feature vectors into an elastic search, at least one cluster of clusters being associated with the at least one candidate entity record;
wherein the ingestion module is configured to index the clusters based on feature vectors determined by the machine learning model based in part on a classification;
utilizing, by at least one processor, at least one machine learning model to map a second set of clusters of the feature vectors in the index associated with the set of high similarity entity records and at least one query entity record;
merging, by the at least one processor, a second set of entity records associated with at least one query entity record and the corresponding high similarity entity records; and
displaying, by the at least one processor, at least one candidate entity record having the record attributes.
|