| CPC B25J 9/1697 (2013.01) [B25J 9/161 (2013.01); B25J 9/162 (2013.01); B25J 9/163 (2013.01)] | 6 Claims |
|
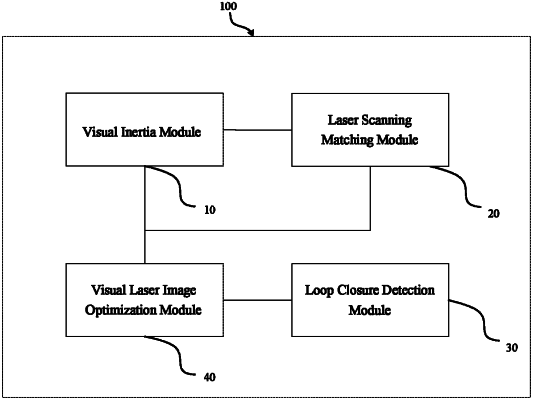
1. A multi-sensor fusion simultaneous localization and mapping (SLAM) system operating on a mobile robot, the multi-sensor fusion SLAM system comprising:
a visual inertia module configured to output pose information;
a laser scanning matching module configured to use the pose information as an initial value, match a laser scanned point cloud with a voxel map to solve an advanced pose, integrate the point cloud into the voxel map according to the advanced pose, and derive a new voxel map, the laser scanning matching module being configured to generate a laser matching constraint;
a loop closure detection module configured to extract an image descriptor of a visual keyframe by using a deep neural network, compare the image descriptor with an image descriptor of a previous keyframe to determine whether a closed loop exists, and if the closed loop exists, determine pose transformation of the two keyframes by using a perspective-n-point (PnP) method, solve a loop closure pose constraint according to the pose transformation and the voxel map, and send the loop closure pose constraint to the visual laser image optimization module; and
a visual laser image optimization module configured to correct an accumulated error of the system according to the pose information, the laser matching constraint, and the loop closure pose constraint after the closed loop occurs;
wherein the visual inertia module includes:
a visual front-end unit configured to select the keyframe;
an inertial measurement unit (IMU) pre-integration unit configured to generate an IMU observation value; and
a sliding window optimization unit configured to jointly optimize a visual reprojection error, an inertial measurement error, and a mileage measurement error;
wherein the visual front-end unit takes a monocular camera or binocular camera as input, the monocular camera or binocular camera being configured to capture initial images,
the visual front-end unit is configured to track feature points of each frame by using a Kanade-Lucas-Tomasi (KLT) sparse optical flow algorithm,
the visual front-end unit includes a detector, the detector detecting corner features and keeping a minimum number of the feature points in each of the initial images, the detector being configured to set a minimum pixel interval between two adjacent feature points, and
the visual front-end unit is configured to remove distortion of the feature points, remove mismatched feature points by using a random sample consensus (RANSAC) algorithm and a fundamental matrix model, and project correctly matched feature points onto a unit sphere;
wherein the laser scanned point cloud is matched with the voxel map to solve the advanced pose by using an iterative closest point (ICP) algorithm;
wherein the laser scanning matching module includes a lidar configured to acquire a scanning point, transform the scanning point according to the pose information and the IMU observation value, and convert the scanning point into a three-dimensional point cloud in a coordinate system where the robot is located at a current moment; and
wherein the loop closure detection module includes:
a similarity detection unit configured to extract an image descriptor of a current keyframe, compare the image descriptor with an image descriptor of a keyframe in a keyframe data set, select a similar keyframe with highest similarity, and insert the similar keyframe into the keyframe data set;
a visual pose solving unit configured to match feature points of the current keyframe and the similar keyframe through a fast feature point extraction and description algorithm, remove mismatched feature points by using a RANSAC algorithm and a fundamental matrix model, and when the number of correctly matched feature points reaches a third threshold, solve relative pose transformation from the current keyframe to the similar keyframe by using the RANSAC algorithm and the PnP method; and
a laser pose solving unit configured to select two voxel maps associated with the current keyframe and the similar keyframe respectively, take the relative pose transformation as the initial value, and match the two voxel maps by using an ICP algorithm, to obtain final relative pose transformation.
|