| CPC A63F 13/54 (2014.09) [G10L 13/02 (2013.01); G10L 17/04 (2013.01); G10L 17/18 (2013.01); G10L 17/22 (2013.01); G10L 19/16 (2013.01); A63F 2300/6072 (2013.01)] | 20 Claims |
|
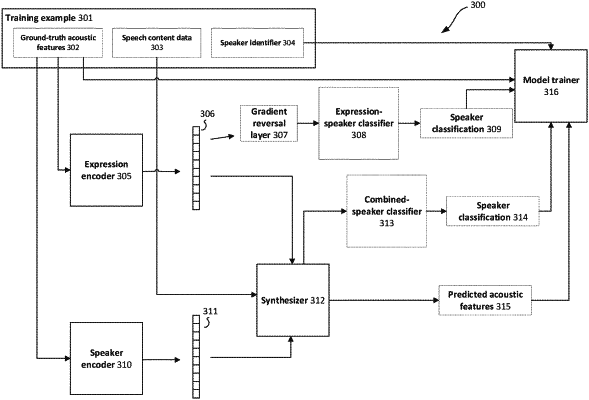
1. A computer-implemented method of training a machine-learned speech audio generation system for use in a video game, the training comprising:
receiving one or more training examples, each training example comprising: (i) ground-truth acoustic features for speech audio, (ii) speech content data representing speech content of the speech audio, and (iii) a ground-truth speaker identifier for a speaker of the speech audio;
for each of the one or more training examples:
generating, by a speaker encoder, a speaker embedding, comprising processing the ground-truth acoustic features;
generating, by an expression encoder, an expression embedding for the training example, comprising processing the ground-truth acoustic features;
classifying, by an expression-speaker classifier, the expression embedding to generate a first speaker classification;
generating, by a speech content encoder of a synthesizer, a speech content embedding, comprising processing the speech content data;
generating a combined embedding, comprising combining the speaker embedding, the expression embedding, and the speech content embedding;
classifying, by a combined-speaker classifier, the combined embedding to generate a second speaker classification;
decoding, by a decoder of the synthesizer, the combined embedding, to generate predicted acoustic features for the training example; and
updating parameters of the machine-learned speech audio generation system to: (i) minimize a measure of difference between the predicted acoustic features of a training example and the corresponding ground-truth acoustic features of the training example, (ii) maximize a measure of difference between the first speaker classification for the training example and the corresponding ground-truth speaker identifier of the training example, and (iii) minimize a measure of difference between the second speaker classification for the training example and the corresponding ground-truth speaker identifier of the training example.
|