| CPC A61B 5/11 (2013.01) [A61B 5/6804 (2013.01); A61B 5/6892 (2013.01); A61B 5/7246 (2013.01); A61B 5/7264 (2013.01); A61B 5/7455 (2013.01); A61B 5/746 (2013.01); A61B 2562/0247 (2013.01)] | 9 Claims |
|
1. A method for identifying activity of a subject relative the ground, the method comprising:
receiving, by a processing system, input tactile sequence data produced from sensor signals generated by a tactile sensing floor covering, the tactile sensing floor covering comprising a piezoresistive pressure sensing matrix having a plurality of sensors and a network of orthogonal electrodes,
wherein each sensor of the plurality of sensors is located at an overlap of the orthogonal electrodes,
wherein the input tactile sequence data comprises sequences of tactile frames spanning respective windows of time, and
wherein the sensor signals generated by the plurality of sensors indicate interactions of the subject with the ground during the respective windows of time;
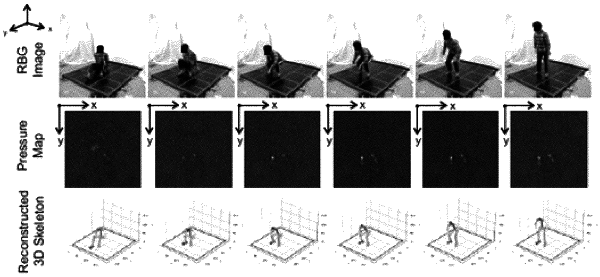
providing, by the processing system, the input tactile sequence data as input to a pose estimation model comprising a convolutional encoder-decoder neural network that was trained using visual data and tactile data, wherein, based on the training, the pose estimation model is configured to predict a 3D human pose based on spatiotemporal tactile information as an input, the convolutional encoder-decoder neural network comprising:
an encoder that maps the input tactile sequence data into a 2D feature map, expands and repeats the 2D feature map to transform the 2D feature map into a 3D feature volume comprising a plurality of voxels, and appends an indexing volume channel to the 3D feature volume indicating a height of each voxel amongst the plurality of voxels; and
a decoder that runs the appended and indexed 3D feature volume through a set of decoding layers to generate a predicted confidence map for each of a plurality of keypoints of the subject;
receiving, by the processing system and as output from the pose estimation model, the predicted confidence map for each of the plurality of keypoints of the subject;
comparing, by the processing system, the predicted confidence map for each of the plurality of keypoints of the subject with information in a database that correlates tactile information to particular activities of the subject or other subjects; and
identifying, by the processing system, a particular activity of the subject based on the comparison.
|