| CPC H04L 65/403 (2013.01) [G06F 3/165 (2013.01); G06F 40/166 (2020.01); G06V 20/41 (2022.01); G10L 15/005 (2013.01); G10L 15/18 (2013.01); G10L 15/22 (2013.01); G10L 25/57 (2013.01)] | 17 Claims |
|
1. A method comprising:
identifying an event in at least one of a user calendar or a conferencing service, the event having a plurality of attendees;
identifying a primary language associated with the event based upon an identity of the attendees;
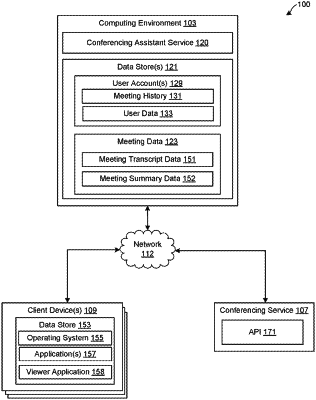
obtaining an audio component and a video component corresponding to the event;
analyzing the audio component and the video component to identify at least one of a visual distraction or an audio distraction, wherein the visual distraction or the audio distraction is associated with a beginning;
identifying an attendee of the event associated with the at least one of a visual distraction or an audio distraction by detecting a spoken language in a portion of the audio component that is spoken by the attendee during the event and obtained from the attendee that is different from the primary language associated with the event, wherein the portion of the audio component originates from a client associated with the attendee;
performing a remedial action with respect to the attendee in response to identifying the at least one of the visual distraction or the audio distraction;
detect an end of the visual distraction or the audio distraction; and
generate a summary of the event from the beginning and the end, the summary generated based upon spoken content and video content using a natural language processing (NLP) model applied to the spoken content from the beginning and the end of the visual distraction and the audio distraction.
|