| CPC G10L 19/008 (2013.01) [G10L 25/03 (2013.01); G10L 25/30 (2013.01); H04S 3/02 (2013.01); H04S 5/00 (2013.01)] | 20 Claims |
|
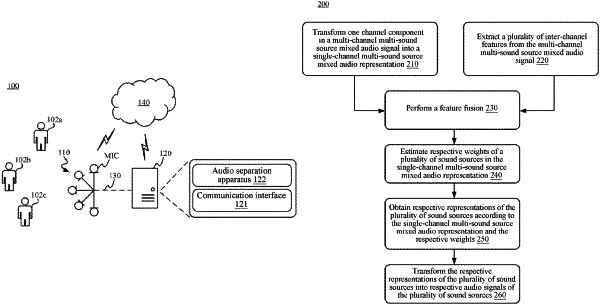
1. An audio separation method of a multi-channel multi-sound source mixed audio signal, performed by a computing device by using an artificial neural network, comprising:
transforming one of a plurality of channel components of the multi-channel multi-sound source mixed audio signal into a single-channel multi-sound source mixed audio representation in a feature space;
performing a two-dimensional dilated convolution on the multi-channel multi-sound source mixed audio signal to extract a plurality of inter-channel features based on a plurality of different values of an inter-channel dilation coefficient z and/or a plurality of different values of an inter-channel stride p and at least one parallel two-dimensional convolutional layer;
performing a feature fusion on the single-channel multi-sound source mixed audio representation and the plurality of inter-channel features to obtain a fused multi-channel multi-sound source mixed audio feature;
estimating respective weights of a plurality of sound sources in the single-channel multi-sound source mixed audio representation based on the fused multi-channel multi-sound source mixed audio feature;
obtaining respective representations of the plurality of sound sources according to the single-channel multi-sound source mixed audio representation and the respective weights; and
transforming the respective representations of the plurality of sound sources into respective audio signals of the plurality of sound sources.
|