| CPC G10L 15/22 (2013.01) [H04N 21/42225 (2013.01); H04N 21/478 (2013.01); H04N 21/4828 (2013.01); G10L 2015/223 (2013.01)] | 16 Claims |
|
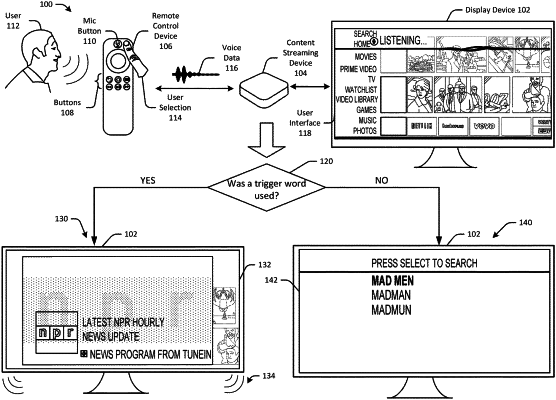
1. A device comprising:
memory that stores computer-executable instructions; and
at least one processor configured to access the memory and execute the computer-executable instructions to:
receive a first incoming voice data indication that is associated with a button interaction at a remote control;
receive first voice data from the remote control;
send the first voice data to a remote server for processing;
receive a set of content search results from the remote server;
cause presentation of the set of content search results;
determine a selection of first content from the set of content search results via the remote control;
cause presentation of first audio content and associated first conversation card by the device;
receive second voice data from the remote control;
determine that the second voice data is a request for second audio data and a second conversation card;
cause, based on the determination that the second voice data is a request for second audio data and a second conversation card, to stop the presentation of the first audio data;
cause presentation of the second audio data and the second conversation card;
determine, based on at least one of a predetermined time for presenting the second audio data or a completion of the second audio data, to return to the presentation of first audio data and first conversation card; and
cause continued presentation of the first conversation card and the first audio data,
wherein the first conversation card includes a template-based data structure for presenting information.
|