| CPC G10L 13/08 (2013.01) [G06F 40/126 (2020.01); G06N 3/044 (2023.01); G06N 3/045 (2023.01); G06N 3/08 (2013.01); G06N 3/088 (2013.01); G10L 13/047 (2013.01); G10L 21/10 (2013.01); G06N 3/048 (2023.01)] | 22 Claims |
|
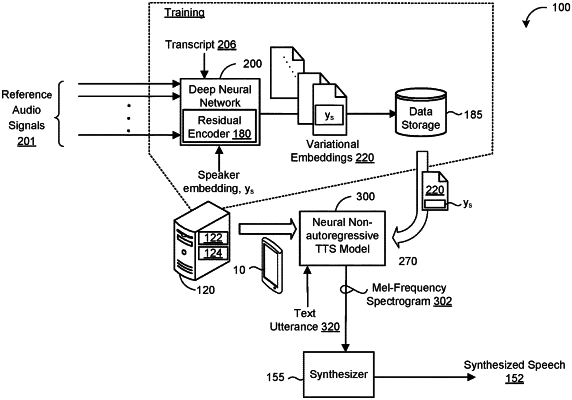
1. A computer-implemented method when executed on data processing hardware causes the data processing hardware to perform operations for training a non-autoregressive text-to-speech (TTS) model, the operations comprising:
receiving training data including a reference audio signal and a corresponding input text sequence, the reference audio signal comprising a spoken utterance and the input text sequence corresponds to a transcript of the reference audio signal;
encoding, using a residual encoder, the reference audio signal into a variational embedding, the variational embedding disentangling style/prosody information from the reference audio signal;
encoding, using a text encoder, the input text sequence into an encoded text sequence;
predicting, using a duration decoder comprising a stack of self-attention blocks followed by two independent projections, based on the encoded text sequence and the variational embedding, a phoneme duration for each phoneme in the input text sequence by:
predicting, using a sigmoid activation following a first one of the two independent projections, a probability of non-zero duration for each phoneme;
predicting, using a softplus activation following a second one of the two independent projections, the phoneme duration for each phoneme;
determining whether the probability of non-zero duration predicted for the corresponding phoneme is less than a threshold value; and
when the probability of non-zero duration is less than the threshold value, zeroing out the phoneme duration predicted for the corresponding phoneme;
determining a phoneme duration loss based on the predicted phoneme durations and a reference phoneme duration sampled from the reference audio signal for each phoneme in the input text sequence
generating, as output from a non-autoregressive spectrogram decoder comprising a stack of self-attention blocks, based on an output of the duration decoder, multiple predicted mel-frequency spectrogram sequences for the input text sequence;
determining a final spectrogram loss based on the multiple predicted mel-frequency spectrogram sequences and a reference mel-frequency spectrogram sequence sampled from the reference audio signal; and
training the TTS model based on the final spectrogram loss and the corresponding phoneme duration loss determined for each phoneme in the input text sequence.
|