| CPC G10L 13/047 (2013.01) [G10L 17/04 (2013.01); G10L 17/06 (2013.01); G10L 17/18 (2013.01); G10L 25/18 (2013.01); G10L 25/30 (2013.01)] | 9 Claims |
|
1. A method for synthesizing multi-speaker speech using an artificial neural network, comprising:
generating and storing a speech learning model for a plurality of users by subjecting a synthetic artificial neural network of a speech synthesis model to learning, based on speech data of the plurality of users;
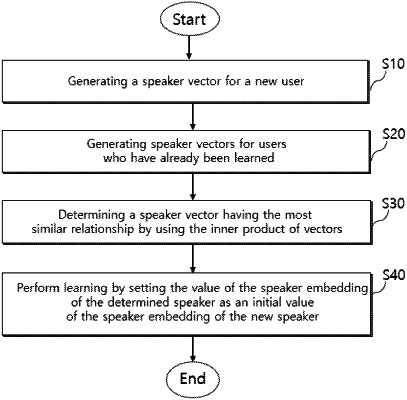
generating speaker vectors for a new user who has not been learned and the plurality of users who have already been learned by using a speaker recognition model;
determining a speaker vector having a most similar relationship with the speaker vector of the new user according to preset criteria out of the speaker vectors of the plurality of users who have already been learned;
generating and learning a speaker embedding of the new user by subjecting the synthetic artificial neural network of the speech synthesis model to learning, by using a value of a speaker embedding of a user for the determined speaker vector as an initial value and based on speaker data of the new user;
wherein the generating a speech learning model for the new user comprises performing the learning of the synthetic artificial neural network of the speech synthesis model only for a preset time that prevents overfitting,
wherein the preset time comprises a range of 10 seconds to 60 seconds, and
wherein the generating speaker vectors comprises generating the speaker vectors using an artificial neural network of the speaker recognition model, by using a speech signal of the user as an input value.
|