| CPC G06V 10/82 (2022.01) [G06T 3/4053 (2013.01)] | 20 Claims |
|
1. A method performed by one or more computers, the method comprising:
receiving a text prompt describing a scene;
processing the text prompt using a text encoder neural network to generate a contextual embedding of the text prompt; and
processing the contextual embedding using a sequence of generative neural networks to generate a final video depicting the scene, wherein the sequence of generative neural networks comprises:
an initial generative neural network configured to:
receive the contextual embedding; and
process the contextual embedding to generate, as output, an initial output video having: (i) an initial spatial resolution, and (ii) an initial temporal resolution; and
one or more subsequent generative neural networks each configured to:
receive a respective input comprising an input video generated as output by a preceding generative neural network in the sequence; and
process the respective input to generate, as output, a respective output video having at least one of: (i) a higher spatial resolution, or (ii) a higher temporal resolution, than the input video,
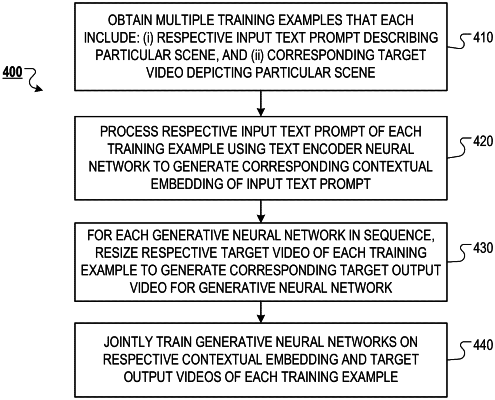
wherein the generative neural networks have been jointly trained on training data comprising a plurality of training examples that each include: (i) respective input text describing a respective scene, and (ii) a corresponding target video depicting the respective scene,
wherein the training examples include image-based training examples,
wherein the respective target video of each image-based training example comprises a respective plurality of individual images each depicting the respective scene described by the corresponding input text, and
wherein jointly training the generative neural networks on the image-based training examples comprised masking out any temporal self-attention and temporal convolution implemented by the generative neural networks.
|