|
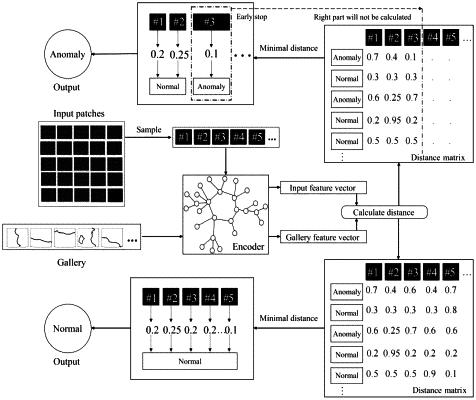
1. A pavement nondestructive and identification method based on small samples, comprising: constructing an original dataset, dividing the original dataset into several patch blocks, sampling the patch blocks, and obtaining samples of the patch blocks; inputting the samples of the patch blocks into a transformer model for feature extraction and target reconstruction, and obtaining a trained transformer model; detecting input pavement sample images based on the trained transformer model; inputting the patch blocks as an input sequence into the transformer model for training to lower resolution and reduce pixels of an image background; and performing feature extraction based on an encoder in the transformer model, comprising, firstly, obtaining the patch blocks by dividing the input equally, and then obtaining image tokens based on a method of linear projection, and adding a position embedding after the tokens are generated to solve position information lost; then, inputting labelled images into the encoder in the transformer for classification; only using class tokens in the classification; outputting different weight combinations in a process of the linear projection, wherein information obtained by the different weight combinations is multi-head information; and performing the feature extraction on the multi-head information based on a multi-head attention mechanism; the target reconstruction comprises: performing pixel-level reconstruction on masked images in the patch blocks based on an a masked autoencoder, dividing the images into patch blocks, randomly masking parts in the patch blocks, and then arranging unmasked patch blocks in sequence, and sending to a transformer encoder to obtain feature vectors; then, inserting masked patch blocks into the feature vectors according to positions in raw images, and then putting into decoder, wherein the decoder reconstructs pixel information to generate original pictures; wherein the masked patch blocks only comprise position information.
|