| CPC G06N 3/08 (2013.01) | 24 Claims |
|
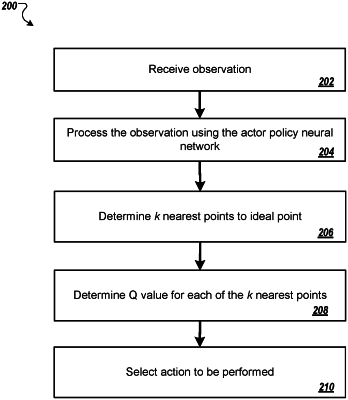
1. A method performed by one or more computers, the method comprising:
receiving a particular observation representing a particular state of an environment; and
selecting an action from a discrete set of actions to be performed by an agent interacting with the environment, wherein each action in the discrete set of actions is represented by a respective point in a multi-dimensional space, and wherein selecting the action comprises:
processing the particular observation using an actor policy network having a plurality of parameters, wherein the actor policy network is a neural network that is configured to receive the particular observation and to process the observation to generate an ideal point in the multi-dimensional space in accordance with first values of the parameters of the actor policy network, wherein the ideal point does not represent any of the actions in the discrete set of actions;
determining, from the points that represent actions in the discrete set of actions, k points based on the ideal point, wherein k is an integer greater than one;
for each point of the k points:
processing the point and the particular observation using a Q network to generate a respective Q value for the action represented by the point, wherein the Q network is a neural network that has a plurality of parameters and that is configured to receive the particular observation and the point and to process the particular observation and the point to generate the respective Q value for the action represented by the point in accordance with first values of the parameters of the Q network; and
selecting, as the action to be performed by the agent, an action from the k actions represented by the k points based on the respective Q values for the k actions represented by the k points.
|