| CPC G06F 9/223 (2013.01) [G06F 9/382 (2013.01); G06F 9/3802 (2013.01); G06F 9/3822 (2013.01); G06F 9/3844 (2013.01)] | 24 Claims |
|
1. A hardware processor core comprising:
a first decode cluster comprising a plurality of decoder circuits;
a second decode cluster comprising a plurality of decoder circuits;
a fetch circuit to fetch a first block of instructions and send the first block of instructions to the first decode cluster for decoding, and fetch a second block of instructions younger in program order than the first block of instructions and send the second block of instructions to the second decode cluster for decoding;
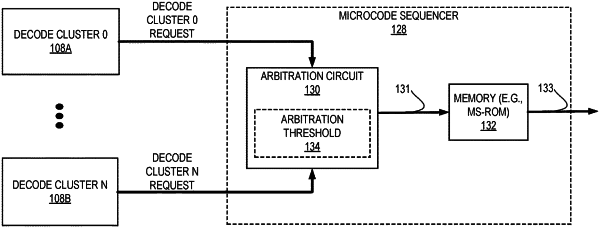
a microcode sequencer comprising a memory that stores a plurality of micro-operations; and
an arbitration circuit to arbitrate access by the first decode cluster and the second decode cluster to a shared read port of the memory, wherein the arbitration circuit is to allow the second decode cluster decoding the second block of instructions access to the shared read port of the memory instead of the first decode cluster decoding the first block of instructions when an instruction of the second block of instructions has a number of corresponding micro-operations in the microcode sequencer below an arbitration threshold.
|