| CPC G06F 40/169 (2020.01) [G06F 3/0482 (2013.01); G06F 16/93 (2019.01)] | 20 Claims |
|
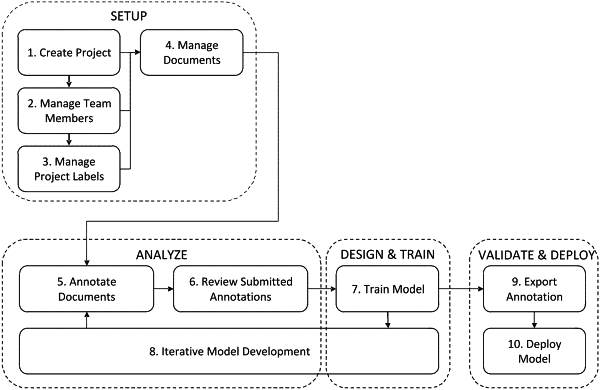
1. A computer-implemented method for annotating an electronic document comprising:
displaying an electronic document, or a page therefrom, on an electronic display device;
displaying a suggestion of labels that may be applicable to categories of text within the electronic document;
receiving a first input from a user indicating a first selection of text in the electronic document;
receiving a second input from the user to assign a first label from the suggested labels to the selected text;
storing the assigned first label, the first selection of text, and the location of the first selection of text for one or more instances of the first selection of text within the electronic document as an annotated electronic document;
receiving a third input from the user indicating a second selection of text in the electronic document;
receiving a fourth input from the user to assign a second label from the suggested labels to the second selection of text;
storing the assigned second label, the second selection of text, and the location of the second selection of text for one or more instances of the second selection of text within the annotated electronic document; and
using the annotated electronic document to train or re-train a first machine learning model to extract text corresponding to the first label and to train or retrain a second machine learning model to extract text corresponding to the second label, wherein the first and second machine learning models are deployed in a continuous learning-based document data extraction pipeline.
|