| CPC G06F 16/906 (2019.01) [G06F 16/93 (2019.01); G06V 10/82 (2022.01); G06V 30/14 (2022.01); G06V 30/18 (2022.01); G06V 30/19 (2022.01); G06V 30/413 (2022.01); G06V 30/418 (2022.01)] | 20 Claims |
|
1. A system comprising:
one or more processors; and
a memory in communication with the one or more processors and storing instructions that, when executed by the one or more processors, are configured to cause the system to:
receive a first single-page document;
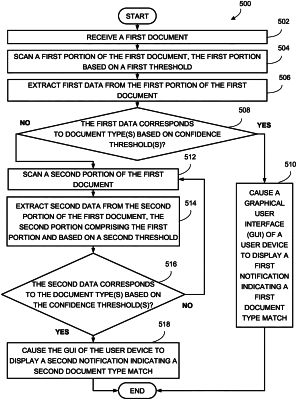
iteratively, until a document type is identified:
scan a portion of the first single-page document, wherein the portion is a fraction of the first single-page document;
extract first text data from the portion of the first single-page document by performing optical character recognition (OCR) on the portion of the first single-page document; and
determine whether the document type is identified by, using a neural network (NN), determining whether the first text data corresponds to one or more document types of a plurality of document types based on one or more confidence thresholds, wherein the portion of the first single-page document scanned increases by a predetermined amount each iteration, the predetermined amount being dynamically updated each iteration by:
determining whether a predefined amount of empty space is identified within the portion of the first single-page document;
responsive to determining the predefined amount of empty space is identified within the portion of the first single-page document, increasing the portion of the first single-page document scanned by a second predetermined amount each iteration until second text data is identified; and responsive to the second text data being identified, automatically reverting to scanning the first single-page document based on an initial predetermined amount with each iteration; and
responsive to determining the first text data corresponds to the one or more document types based on the one or more confidence thresholds, cause a graphical user interface (GUI) of a user device to display a first notification indicating a first document type match.
|