| CPC G10L 19/018 (2013.01) [G10L 21/0224 (2013.01); G10L 21/0232 (2013.01); G10L 21/0272 (2013.01)] | 17 Claims |
|
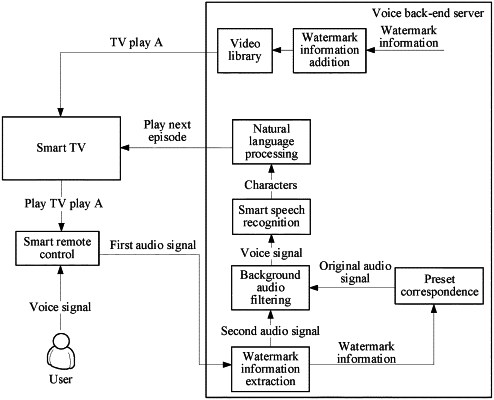
1. A method for filtering out a background audio signal, performed by an electronic device, the method comprising:
obtaining, by the electronic device from a collection device, a first audio signal collected during playing of the background audio signal on a playback device, based on a collection start instruction received from a user during a play of the playback device,
wherein the first audio signal comprises a target audio signal, the target audio signal being a voice signal corresponding to a user voice instruction, wherein the background audio signal is an audio signal obtained by adding watermark information to an original audio signal, and wherein the collection device is different from the playback device and the electronic device,
wherein the watermark information is added to the original audio signal to generate the background audio signal, and the generating the background audio signal comprises:
converting the original audio signal from a time-domain signal to a frequency-domain signal, and
adding the watermark information to the frequency-domain signal of the original audio signal, wherein the addition generates the background audio signal in a frequency-domain;
separating the first audio signal, to obtain the watermark information and a second audio signal without the watermark information, the second audio signal comprising the target audio signal, wherein the separating the first audio signal comprises:
transforming a first audio time-domain signal to obtain a first audio frequency-domain signal;
separating the first audio frequency-domain signal, to obtain the watermark information and a second audio frequency-domain signal without the watermark information; and
inversely transforming the second audio frequency-domain signal to obtain a second audio time-domain signal;
querying a preset correspondence based on the watermark information to obtain the original audio signal, the preset correspondence comprising a correspondence between the original audio signal and the watermark information added to the original audio signal;
based on both the second audio signal and the original audio signal being in a same audio time-domain, determining a difference between the second audio signal and the original audio signal, wherein the determining the difference comprises:
transforming the second audio time-domain signal to obtain the second audio frequency-domain signal;
transforming the original audio signal from the time-domain signal to the frequency-domain signal; and
determining, as a target audio frequency-domain signal, a difference between the second audio frequency-domain signal and the frequency-domain signal of the original audio signal;
inversely transforming the target audio frequency-domain signal to obtain the target audio signal in a time domain; and
obtaining the target audio signal in the time domain,
wherein each time the watermark information is added to the original audio signal, the preset correspondence between the original audio signal and the watermark information is added to a preset database,
wherein a plurality of original audio signals of which a popularity is greater than a preset threshold are selected from a larger number of original audio signals, the popularity being determined based on one or more of an amount of a play of a corresponding original audio signal, a search volume for the corresponding original audio signal, and a number of users followed by a publisher of the corresponding original audio signal,
wherein a plurality of background audio signals are generated by adding watermark information to the selected plurality of original audio signals, and
wherein watermark information is not added to remaining original audio signals, of which a popularity is less than the preset threshold, of the larger number of original audio signals.
|