| CPC G10L 15/22 (2013.01) [G06F 3/0481 (2013.01); G06F 3/167 (2013.01); G06N 3/042 (2023.01); G10L 15/063 (2013.01); G10L 15/16 (2013.01); G10L 15/1815 (2013.01); G10L 15/183 (2013.01); G10L 15/30 (2013.01); G10L 2015/223 (2013.01)] | 17 Claims |
|
1. A method for controlling an electronic device, the method comprising:
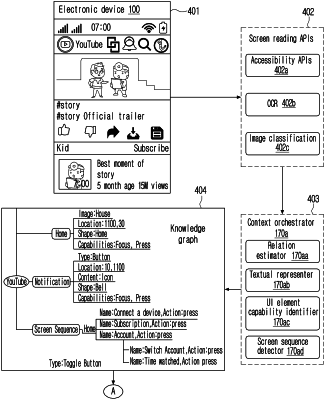
identifying, by the electronic device, at least one user interface (UI) element displayed on a screen of the electronic device using at least one of screen reading application programming interface (API), optical character recognition (OCR), or image classification;
identifying, by the electronic device, at least one characteristic of the identified at least one UI element;
predicting, by the electronic device, a natural language utterance based on the at least one characteristic of the identified at least one UI element;
generating, by the electronic device, a database including the predicted natural language utterance corresponding to the identified at least one UI element;
based on receiving a voice input, identifying, by the electronic device, whether an utterance of the received voice input matches the natural language utterance included in the generated database; and
based on identifying that the utterance of the voice input matches the natural language utterance, automatically accessing, by the electronic device, the at least one UI element,
wherein the at least one characteristic of the identified at least one UI element comprises:
at least one of positions of respective UI elements, relative positions of the respective UI elements for other UI elements, functions of the respective UI elements, capabilities of the respective UI elements, types of the respective UI elements, or appearances of the respective UI elements,
wherein the at least one UI element comprises a non-textual UI element,
wherein the predicting of the natural language utterance comprises determining a textual representation of the non-textual UI element and a viewable relative position of the non-textual UI element among viewable positions of the other UI elements,
wherein the generating of the database comprises:
identifying similarities between respective UI elements based on positions of the respective UI elements, and a similarity between at least one of relative positions of the respective UI elements, functions of the respective UI elements, capabilities of the respective UI elements, or shapes of the respective UI elements;
acquiring a knowledge graph by clustering the respective UI elements based on the identified similarities; and
storing the knowledge graph in the database, and
wherein the method further comprising:
performing a semantic translation on the knowledge graph to acquire natural language variations for at least one of a single-step intent or a multi-step intent;
identifying at least one action and at least one action sequence for at least one of the single-step intent or the multi-step intent using the knowledge graph; and
dynamically generating a natural language model for predicting a natural utterance of the identified UI element by mapping the acquired natural language variations with the identified at least one action and the identified at least one action sequence.
|