| CPC G10L 15/1815 (2013.01) [G06F 3/14 (2013.01); G06F 3/167 (2013.01); G10L 15/22 (2013.01); G10L 25/51 (2013.01); G10L 25/78 (2013.01); G10L 2015/088 (2013.01)] | 20 Claims |
|
1. A computer-implemented method for execution on a system, the method comprising:
receiving audio data comprising individual audio streams from a plurality of computers participating in a communication session;
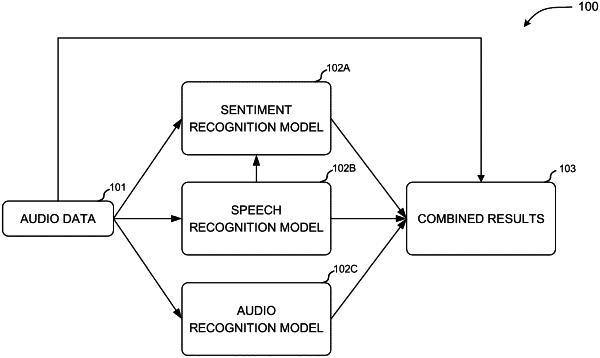
utilizing a sentiment recognition model to identify a sentiment from a speech input of a user, wherein the speech input is provided by at least one audio stream generated by at least one computer of the plurality of computers, wherein the sentiment recognition model is configured to identify the sentiment of the user in response to determining that a volume of the speech input meets one or more volume criteria;
utilizing a speech recognition model to generate a transcript of spoken words that are identified in the audio data that is received from the plurality of computers, wherein the speech recognition model is also configured to identify keywords of the speech input of the user, wherein the speech recognition model is configured to identify keywords of the speech input by an analysis of the at least one audio stream generated by at least one computer, where the keywords are identified by the use of a keyword list that is based, at least in part, on user activity of the communication session, wherein the speech recognition model is configured to modify the keyword list based on an input indicating focus on one or more words, wherein the one or more words identified in the input are added to the keyword list;
utilizing an audio recognition model to identify one or more events based on the analysis of a non-speech audio input identified in the at least one audio stream generated by at least one computer of the plurality of computers, wherein the audio recognition model is configured to distinguish the speech input from the non-speech audio input and identify the one or more non-speech events based on audio characteristics of the non-speech audio input; and
generating a user interface depicting the transcript of spoken words of the users of the communication session, wherein arrangement attributes of the user interface are selected based on the sentiment that is determined from an analysis of the speech input of the user by the sentiment recognition model, wherein the display of the transcript is arranged to distinguish keywords that are identified by the speech recognition model, and wherein the user interface comprises visual indicators that are displayed in coordination with text of the transcript to indicate the one or more non-speech events determined by the audio recognition model.
|