| CPC G10L 15/063 (2013.01) [G10L 15/02 (2013.01); G10L 15/183 (2013.01); G10L 15/22 (2013.01); G10L 2015/025 (2013.01); G10L 2015/0635 (2013.01)] | 20 Claims |
|
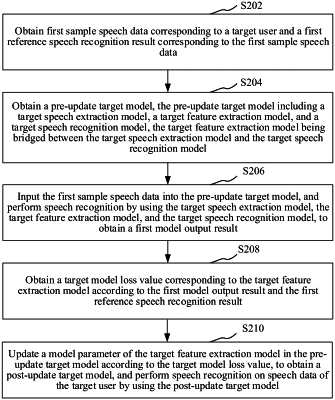
1. A speech recognition method, performed by a computer device, and comprising:
obtaining first sample speech data corresponding to a target user and a first reference speech recognition result corresponding to the first sample speech data;
obtaining a pre-update target model, the pre-update target model comprising a target speech extraction model, a target feature extraction model, and a target speech recognition model, wherein the target feature extraction model bridges the target speech extraction model and the target speech recognition model, wherein the target speech recognition model is trained using a plurality of training audio frames each corresponding to a respective target phoneme class, and wherein at least one model parameter, of the target speech recognition model, is adjusted based on a center loss value that indicates a difference between an encoded feature, of a first training audio frame corresponding to a first target phoneme class, and a phoneme class center vector corresponding to the first target phoneme class;
inputting the first sample speech data into the pre-update target model, and performing speech recognition by using the target speech extraction model, the target feature extraction model, and the target speech recognition model, to obtain a first model output result;
obtaining a target model loss value corresponding to the target feature extraction model according to the first model output result and the first reference speech recognition result; and
updating a model parameter of the target feature extraction model in the pre-update target model according to the target model loss value, to obtain a post-update target model, and performing speech recognition on speech data of the target user by using the post-update target model.
|