| CPC G06V 30/414 (2022.01) [G06F 40/226 (2020.01); G06V 30/413 (2022.01); G06V 30/418 (2022.01); G06F 16/93 (2019.01)] | 18 Claims |
|
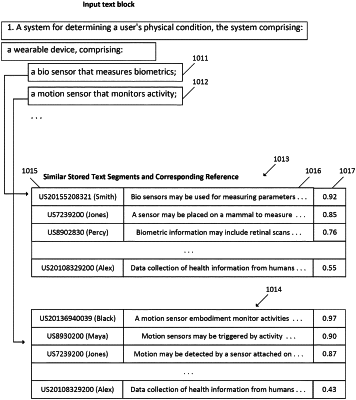
1. A computer-implemented method for performing text search using machine learning, comprising:
receiving an input text block, the input text block comprising a patent claim;
splitting the patent claim into clauses;
performing, by a first machine learning model, a document similarity matching between each the input text block and a plurality of reference documents;
identifying, based on the document similarity matching, a first subset of documents;
performing, by a second machine learning model, a text similarity matching between each clause and a plurality of stored text portions for each document in the identified subset of document, wherein the text similarity matching generates a plurality of similarity scores measuring the similarity between each clause and the plurality of stored text portions;
generating, for each clause, a clause subset of documents from the first subset of documents;
generating, for each clause, a ranked list of text segments from the clause subset, wherein the ranking is based on text similarity between the clause and the stored text portions of the documents in the clause subset;
identifying, based at least partly on the ranked list of text segments for each clause and one or more combination criteria, a combination of final documents and text segments of said final documents; and
displaying, for each clause, one or more text segments from one or more final documents based at least partly on the ranking of the text segments and the one or more combination criteria.
|