| CPC G06T 15/005 (2013.01) [G06N 3/08 (2013.01); G06T 1/20 (2013.01); G06T 1/60 (2013.01); G06T 15/40 (2013.01); G06T 17/20 (2013.01)] | 20 Claims |
|
1. A graphics processor comprising:
a block of execution resources;
a cache memory;
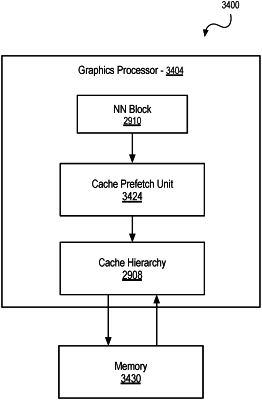
a cache memory prefetcher having an adjustable prefetch pattern that is adjustable to a learned prefetch pattern, the learned prefetch pattern learned by a neural network; and
circuitry including a programmable neural network unit, the programmable neural network unit comprising a network hardware block including circuitry to perform neural network operations and activation operations for a layer of the neural network, the programmable neural network unit addressable by cores within the block of graphics cores and the neural network hardware block configured to perform operations associated with a neural network configured to determine a prefetch pattern for the cache memory prefetcher, wherein the prefetch pattern determined for the cache memory prefetcher is the learned prefetch pattern, the cache memory prefetcher is to prefetch data according to the learned prefetch pattern, and the learned prefetch pattern is based at least in part on a memory access pattern associated with a workload executed via the block of execution resources, wherein the neural network hardware block is configured, via the neural network, to:
recognize the workload executed via the block of execution resources as the workload associated with the learned prefetch pattern based at least in part on the memory access pattern associated with the workload; and
configure the prefetch pattern for the cache memory prefetcher to the learned prefetch pattern for use with the workload, the learned prefetch pattern one of a plurality of learned prefetch patterns associated with a plurality of workloads.
|