| CPC G06F 16/9024 (2019.01) | 19 Claims |
|
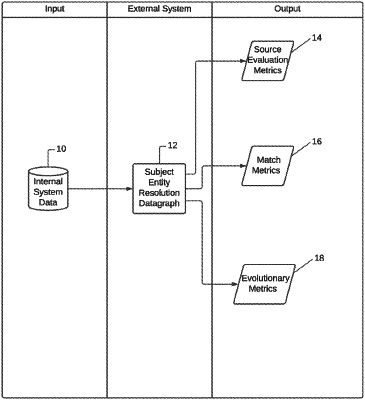
1. A machine for analyzing a subject entity resolution data graph against peer data structures, the subject entity resolution data graph comprising a plurality of asserted relationships, each asserted relationship comprising a set of entity data for a particular entity and connections between the entity data, the machine comprising:
at least one processor; and
at least one memory that stores executable instructions that, when executed by the at least one processor, facilitates performance of operations, the operations comprising:
screening a plurality of peer entity resolution data structures to produce a set of trustworthiness metrics, wherein the set of trustworthiness metrics are applied to produce a plurality of candidate data structures, wherein the plurality of candidate data structures form a subset of the plurality of peer entity resolution data structures;
creating combinations of each one of the plurality of candidate data structures with each other one of the plurality of candidate data structures and submitting each combination to an evolutionary analysis process to produce a plurality of oracles, wherein the plurality of oracles form a subset of the plurality of candidate data structures; and
deriving asserted relationships from each of the plurality of candidate data structures, matching those candidate data structure asserted relationships against the subject entity resolution data graph to produce a set of matching results by partitioning the subject entity resolution data graph into disjoint significantly smaller subsets, wherein each subset is self-contained, and wherein the partitioning starts with aggregation of entities sharing a best postal address, then expands to fields providing a general locality index, and wherein when the partitioning converges a feedback loop is performed in terms of a set of defining similarity indices to determine whether a small number of adjustments to partition elements is needed, and then performing data-level and entity-level evaluation against the set of matching results to produce a set of quality metrics for the subject entity resolution data graph.
|