| CPC H04N 5/2222 (2013.01) [G06F 40/117 (2020.01); G06F 40/169 (2020.01); G06V 20/40 (2022.01); G06V 40/18 (2022.01); G10L 15/18 (2013.01); G10L 15/22 (2013.01); G10L 25/57 (2013.01); G11B 27/031 (2013.01)] | 20 Claims |
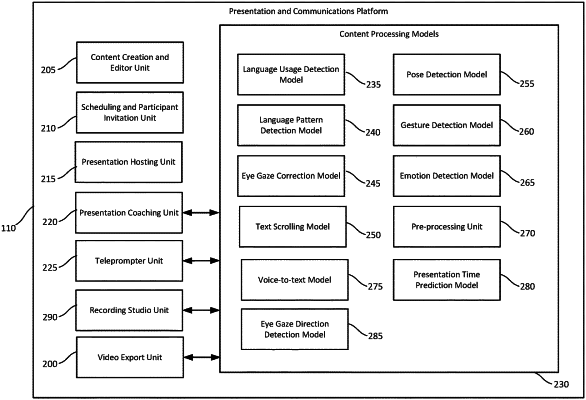
|
1. A data processing system comprising:
a processor; and
a machine-readable medium storing executable instructions that, when executed, cause the processor to perform operations comprising:
causing a teleprompter transcript associated with a presentation to be displayed on a display of a computing device associated with a presenter of the presentation;
receiving audio content of the presentation including speech of the presenter in which the presenter is reading the teleprompter transcript;
analyzing the audio content of the presentation using a first machine learning model to obtain a real-time textual representation of the audio content, the first machine learning model being a natural language processing model trained to receive audio content including speech and to convert the audio content into a textual representation of the speech in the audio content;
analyzing the real-time textual representation and the teleprompter transcript with a second machine learning model to obtain transcript position information, the second machine learning model being configured to receive a first textual input and a second textual input and determine a position of the first textual input; and
automatically scrolling the teleprompter transcript on the display of the computing device based on the transcript position information on the display of the computing device associated with the presenter.
|