| CPC H04L 9/008 (2013.01) [G06F 7/728 (2013.01); G06F 17/16 (2013.01); H04L 9/3093 (2013.01)] | 20 Claims |
|
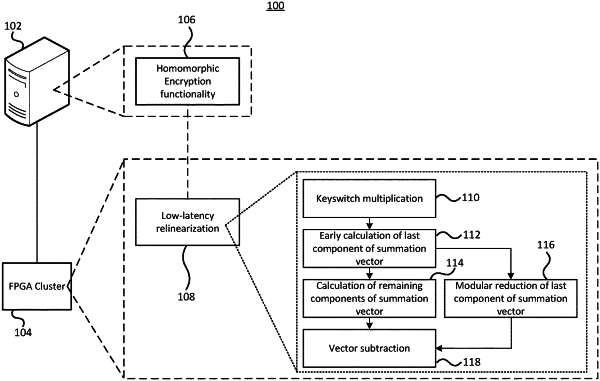
1. A low-latency relinearization method implemented by a field programmable gate array (FPGA) cluster comprising:
receiving at the FPGA cluster a polynomial vector comprising R components; and
performing modular reduction on the polynomial vector to generate a polynomial matrix comprising R+1 rows and L columns;
multiplying the polynomial matrix by a first Keyswitch matrix to generate a first intermediate polynomial matrix;
summing a last row of the first intermediate polynomial matrix to generate a first early-summation element and performing a modular reduction on the first early-summation element to generate a first early-summation vector;
summing remaining rows of the first intermediate polynomial matrix to generate a first summation vector;
subtracting the first early-summation vector from the first summation vector to generate a first subtraction-result vector;
multiplying the first subtraction-result vector by an inverse moduli vector to generate a first result vector; and
outputting from the FPGA cluster the first result vector.
|