| CPC H04L 65/80 (2013.01) [H04L 65/70 (2022.05); H04N 19/162 (2014.11); H04N 19/184 (2014.11); H04N 19/70 (2014.11)] | 24 Claims |
|
1. A method of video processing, comprising:
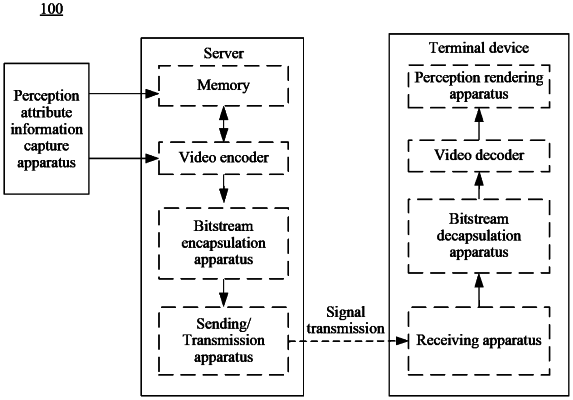
obtaining, by a server, source video data;
determining, by the server, at least one object having perception attribute information to be encoded in the source video data, wherein the perception attribute information indicates a human body perception attribute of the at least one object and is used to indicate a property presented when the at least one object is perceived by a human user;
obtaining, by the server, the perception attribute information of the at least one object and spatial location information of the at least one object, wherein the spatial location information is used to indicate a spatial location of the at least one object;
adding, by the server, the perception attribute information and the spatial location information to a video bitstream generated after the source video data is encoded or a video file of the source video data, wherein the video file is used to describe a video attribute of the source video data; and
encapsulating, by the server, the video bitstream or the video file
wherein
perception attribute information of at least one target object and spatial location information of the at least one target object are subsequently obtained in the video bitstream or the video file, wherein the at least one object comprises the at least one target object; and
perception rendering is performed on a perception attribute of the at least one target object based on behavior of the human user, the perception attribute information of the at least one target object and the spatial location information of the at least one target object;
the performance of the perception rendering on the perception attribute of the at least one target object comprises:
determining a scent strength value of a first target object in the at least one target object at a current location of the human user based on the current location of the human user, spatial location information of the first target object, and a maximum scent strength of the first target object, and
emitting a scent corresponding to the scent strength value and a scent code of the first target object; or
determining a touch strength value of a second target object in the at least one target object at a touch point of the human user based on a current location of the touch point of the human user, spatial location information of the second target object, and a maximum tactility strength of the second target object, and
feeding back tactility perception corresponding to the touch strength value and a tactility code of the second target object to the human user.
|