| CPC G10L 17/06 (2013.01) [G10L 15/18 (2013.01); G10L 17/02 (2013.01); G10L 17/12 (2013.01); G10L 17/16 (2013.01); G10L 17/22 (2013.01); G10L 15/20 (2013.01); G10L 15/26 (2013.01); G10L 2015/025 (2013.01); G10L 2015/088 (2013.01)] | 20 Claims |
|
1. A computer-implemented method comprising:
under control of one or more computing devices configured to execute specific instructions,
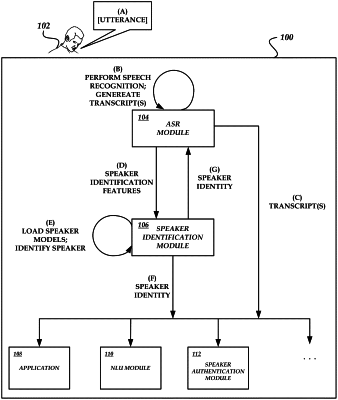
receiving audio data representing an utterance;
generating speaker identifier data based at least partly on the audio data;
generating natural language understanding (“NLU”) data based at least partly on analyzing the audio data using an NLU subsystem, wherein the NLU data represents a command;
identifying, based at least partly on the NLU data, an application of a plurality of applications to generate at least a portion of a response to the utterance; and
sending the speaker identifier data to the application, wherein the application generates a response, customized to a user profile of the application, based on the speaker identifier data.
|