| CPC G10L 15/22 (2013.01) [G06F 3/165 (2013.01); G06F 3/167 (2013.01); H04N 21/42203 (2013.01); G10L 2015/223 (2013.01)] | 20 Claims |
|
1. A playback device comprising:
at least one audio transducer;
a network interface;
at least one microphone;
at least one processor; and
at least one non-transitory computer-readable medium comprising instructions that are executable by the at least one processor such that the playback device is configured to:
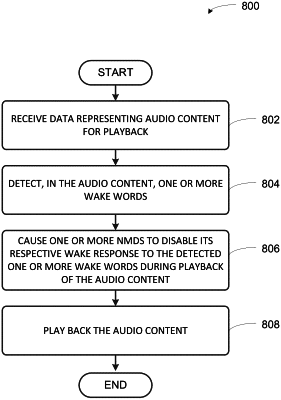
receive audio content for playback by the playback device;
provide a sound data stream representing the received audio content to (i) a first wake-word engine and (ii) a second wake-word engine, wherein the first wake-word engine is operable to (a) generate a first wake-word response when the first wake-word engine detects a first wake word in a microphone sound data stream representing sound detected by the at least one microphone of the playback device and (b) send sound data representing the sound detected by the at least one microphone to a first voice assistant when the first wake-word response is generated, and wherein the second wake-word engine is operable to (a) generate a second wake-word response when the second wake-word engine detects at least one second wake-word in the microphone sound data stream representing sound detected by the at least one microphone and (b) send sound data representing the sound detected by the at least one microphone to a second voice assistant when the second wake-word response is generated;
play back a first portion of the audio content via the at least one audio transducer;
detect, via the first wake-word engine, that a second portion of the received audio content includes sound data matching the first wake word;
before the second portion of the received audio content that includes the sound data matching the first wake word is played back, temporarily disable the first wake-word response of the first wake-word engine and the second wake-word response of the second wake-word engine; and
play back the second portion of the audio content via the at least one audio transducer.
|