| CPC G10L 15/005 (2013.01) [G10L 15/07 (2013.01); G10L 15/16 (2013.01); G10L 2015/0631 (2013.01)] | 20 Claims |
|
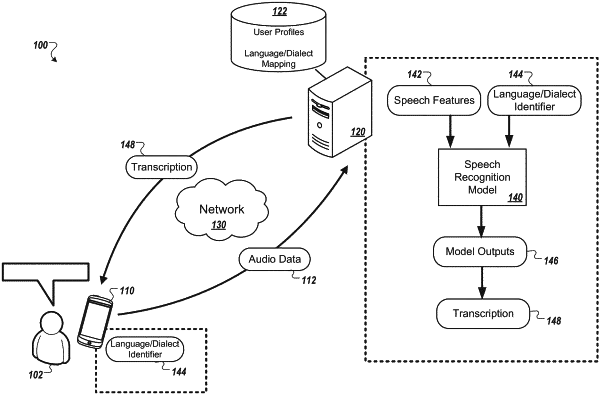
1. A computer-implemented method of performing speech recognition, the method when executed on data processing hardware causes the data processing hardware to perform operations comprising:
receiving audio data indicating audio characteristics of an utterance;
providing, as input to an automatic speech recognition model, speech features determined based on the audio data, wherein the speech recognition model has been trained, using cluster adaptive training:
to recognize linguistic units for each of multiple different languages or dialects, with each of the multiple different languages or dialects corresponding to a separate cluster;
to receive, as input, different identifiers that specify the different clusters corresponding to the respective languages or dialects; and
to compute a weighted sum of the means of the different clusters, wherein the means of the different clusters are weighted based on the different identifiers;
based on the speech features provided as input to the speech recognition model, generating, as output from the speech recognition model at each of a plurality of time steps, an output vector at the corresponding time step indicating a probability distribution over a predetermined set of linguistic units for each of the multiple different languages or dialects the speech recognition model has been trained to recognize; and
providing, as an output of the automated speech recognition model, a transcription of the utterance generated based on the output vectors generated as output from the speech recognition model at each of the plurality of time steps.
|