| CPC G10L 13/08 (2013.01) [G06F 3/165 (2013.01); G10L 13/047 (2013.01); H04L 67/306 (2013.01)] | 17 Claims |
|
1. A method comprising:
receiving, from a client device of a posting user of an online system, a script for a voice-based content item;
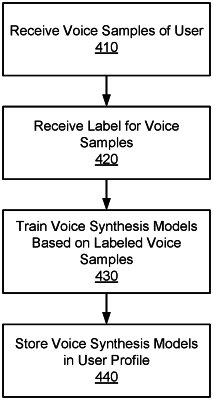
retrieving a voice synthesis model stored in a user profile of the posting user, the voice synthesis model trained at least based on a plurality of voice samples of the posting user, wherein the script comprises an indication of a mood for the voice-based content item, and wherein retrieving the voice synthesis model comprises selecting the voice synthesis model from a plurality of candidate voice synthesis models stored in the user profile of the posting user, each different candidate voice synthesis models trained using training data corresponding to a different mood, the selection of the voice synthesis model selected from the plurality of candidate voice synthesis models based on the indication of the mood for the voice-based content item matching a mood with which the voice synthesis model's training data was labeled;
generating a synthetic audio stream using the retrieved voice synthesis model and based on the received script;
presenting the generated synthetic audio stream to the posting user;
receiving instructions for modifying the synthetic audio stream;
generating a second audio stream based on the received instructions;
composing the voice-based content item based on the generated second audio stream; and
presenting the voice-based content item to a viewing user of the online system.
|