| CPC G06V 20/698 (2022.01) [G06F 16/532 (2019.01); G06V 10/70 (2022.01); G06V 10/7715 (2022.01); G06V 10/82 (2022.01); G06V 20/695 (2022.01); G06V 20/70 (2022.01); G06V 2201/03 (2022.01)] | 26 Claims |
|
1. A method of automatic multi-tagging of whole slide histopathology images comprising:
a) receiving a digital whole slide image;
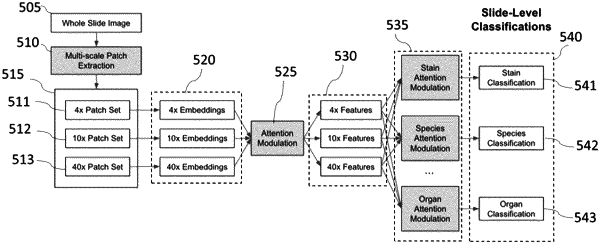
b) sampling a plurality of non-background patches from the whole slide image at a plurality of magnifications;
c) applying a machine learning model to predict multiple slide-level tags from the plurality of non-background patches, wherein the machine learning model comprises:
i. a first module configured to extract a visual feature representation of each patch;
ii. a second module configured to modulate patch features by providing the extracted visual feature representations as inputs to a first attention aggregation mechanism performing operations comprising: mapping each visual feature representation into different attention-weighted features through multi-head attentions and outputting a weighted patch feature comprising an aggregation of the visual feature representations and the attention-weighted features;
wherein the machine learning model operates in a multi-scale mode utilizing the patches at the plurality of magnifications to identify both patch features and magnification levels most discriminant for the multi-tagging;
iii. a third module configured to construct slide-level tags identifying tag classifications by providing the weighted patch features to a plurality of second attention aggregation mechanisms, one per output head, each performing operations comprising: mapping each weighted patch feature into different attention-weighted features through multi-head attentions, and outputting a slide-level tag comprising an aggregation of the attention-weighted features; and
d) associating the multiple slide-level tags with the digital whole slide image.
|