| CPC G06V 10/82 (2022.01) [G06F 16/5838 (2019.01); G06F 16/784 (2019.01); G06F 18/24143 (2023.01); G06V 10/764 (2022.01); G06V 10/955 (2022.01); G06V 40/10 (2022.01); G06V 40/103 (2022.01); G06V 40/23 (2022.01)] | 25 Claims |
|
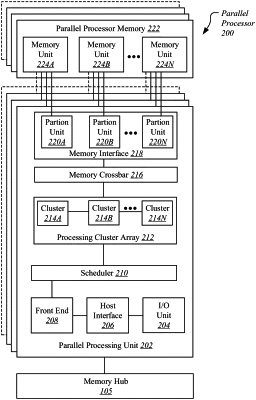
1. A graphics processor comprising:
a plurality of memory controllers associated with a plurality of memory partitions;
a level-two (L2) cache including a plurality of cache partitions associated with the plurality of memory partitions;
a processing cluster array including a plurality of processing clusters coupled with the plurality of memory controllers, each processing cluster of the plurality of processing clusters including a plurality of streaming multiprocessors, the processing cluster array configured for partitioning into a plurality of partitions, the plurality of partitions including:
a first partition including a first plurality of streaming multiprocessors configured to perform operations for a first neural network, the operations for the first neural network isolated to the first partition; and
a second partition including a second plurality of streaming multiprocessors configured to perform operations for a second neural network, the operations for the second neural network are isolated to the second partition and protected from operations performed for the first neural network.
|