| CPC G06T 7/251 (2017.01) [G06T 2207/10028 (2013.01); G06T 2207/20081 (2013.01); G06T 2207/20084 (2013.01)] | 9 Claims |
|
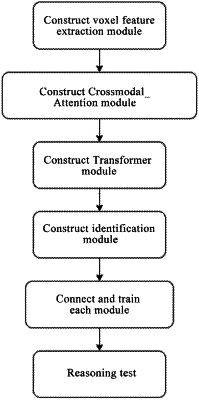
1. A system for detecting a moving target based on multi-frame point clouds, comprising:
a voxel feature extraction module,
a transformer module comprising a cross-modal attention module, and
an identification module,
wherein the voxel feature extraction module is configured to voxelize a continuous frame point cloud sequence and extract a feature tensor sequence;
wherein the transformer module is configured to:
acquire the feature tensor sequence,
fuse a first feature tensor with a second feature tensor by the cross-modal attention module,
fuse a fused result of the first feature tensor and the second feature tensor, with a third feature tensor,
fuse a fused result of the fused result of the first feature tensor and the second feature tensor, and a third feature tensor, with a fourth feature tensor, and
repeat the fusing steps with a next feature tensor, until a last feature tensor is fused, to obtain a final fused feature tensor;
wherein the cross-modal attention module is configured to:
match and fuse two feature tensors according to an attention mechanism to obtain a fused feature tensor by convolution neural network fusion;
wherein the identification module is configured to extract features from the final fused feature tensor and output detection information of a target; and
wherein the matching and fusion of the cross-modal attention module is as follows:
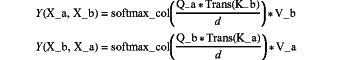 where Q_a=X_a*W_Q and Q_b=X_b*W_Q represent Query in the attention mechanism, respectively; K_a=X_a*W_K and K_b=X_b*W_K represent Key in the attention mechanism, respectively; V_a=X_a*W_V and V_b=X_b*W_V represent Value in the attention mechanism, respectively; X_a and X_b represent two feature tensors to be fused, respectively; W_Q, W_K and W_V represent trainable weight matrices, respectively; d represents the dimensions of Q_a and K_b and Q_b and K_a, respectively; Trans( ) represents a matrix transposition operation; and softmax_col( ) represents a matrix normalization operation by column; and
fuse Y(X_a, X_b) and Y(X_b, X_a) by a convolutional neural network to obtain the fused feature tensor:
Crossmodal Attention(X_a,X_b)=Conv(Y(X_a, X_b),Y(X_b, X_a))
where Conv ( ) represents the convolutional neural network.
|