| CPC G06T 11/60 (2013.01) [G06N 3/045 (2023.01); G06N 3/088 (2013.01); G06T 3/0006 (2013.01); G06T 3/40 (2013.01); G06T 9/002 (2013.01)] | 26 Claims |
|
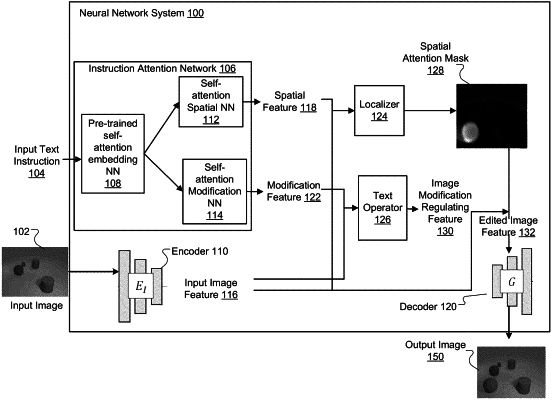
1. A method for generating an output image from an input image and an input text instruction that specifies a location and a modification of an edit applied to the input image using a neural network that comprises an image encoder, an image decoder, and an instruction attention network:
receiving the input image and the input text instruction;
extracting, from the input image, an input image feature that represents features of the input image using the image encoder;
generating a spatial feature and a modification feature from the input text instruction using the instruction attention network, wherein the spatial feature encodes location information of the edit in the input image, and the modification feature encodes modification information of the edit in the input image;
generating an edited image feature from (i) the input image feature extracted from the input image, (ii) the spatial feature generated by using the spatial neural network, and (iii) the modification feature generated by using the modification neural network, comprising:
generating a spatial attention mask from the spatial feature and the input image feature, wherein the spatial attention mask specifies a desired region of the edit in the input image,
generating an image modification regulating feature from the modification feature and the input image feature, wherein the image modification regulating feature regulates the modification of the input image as directed by the input text instruction, and
generating the edited image feature from the input image feature, the spatial attention mask, and the image modification regulating feature; and
generating the output image from the edited image feature using the image decoder.
|