| CPC G06N 5/04 (2013.01) [G06F 16/258 (2019.01); G06N 20/00 (2019.01)] | 14 Claims |
|
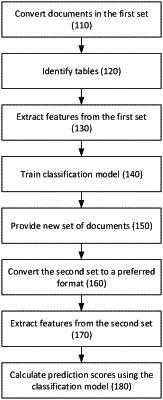
1. A method comprising:
receiving a training set of documents, each document including a plurality of first labels associated with first data points, wherein each document displays the plurality of first labels and the first data points in a table;
receiving a map demonstrating associations between respective first labels of the documents;
extracting a first feature of each document in the training set, wherein the first feature is a similarity of a first position of at least one of the plurality of first labels in a first document to a second position of at least one of the plurality of first labels in a second document;
extracting a second feature of each document in the training set, wherein the second feature is another similarity of at least one of the plurality of first labels appearing before or after at least another one of the plurality of first labels in the first document to at least one of the plurality of first labels appearing before or after at least another one of the plurality of first labels in the second document;
training a classification model using the training set of documents, the map, the first feature, and the second feature;
receiving a second set of documents, each document including a plurality of second labels associated with second data points;
extracting a third feature of each document in the second set;
providing the second set of documents and the third feature to the classification model; and
receiving a prediction score from the classification model, the prediction score indicating a likelihood of two second labels being associated with each other.
|