| CPC G06N 3/006 (2013.01) [A63F 13/67 (2014.09); G06F 18/214 (2023.01); G06N 20/00 (2019.01); G06V 10/764 (2022.01); G06N 3/02 (2013.01)] | 17 Claims |
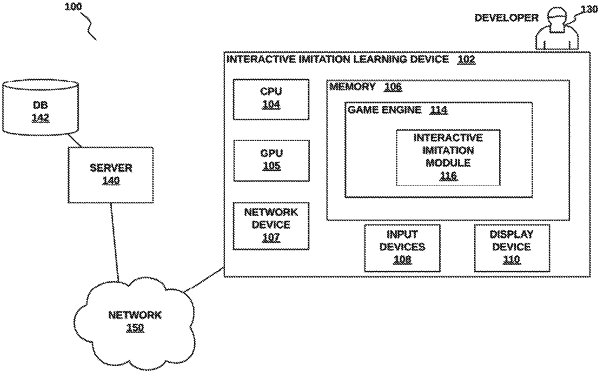
|
1. A system comprising:
one or more computer processors;
one or more computer memories; and
a set of instructions incorporated into the one or more computer memories, the set of instructions configuring the one or more computer processors to perform operations, the operations comprising:
receiving first input data from one or more input devices, the first input data describing a first set of example actions;
using inverse reinforcement learning to estimate a reward function for the first set of example actions;
using the reward function and the first set of example actions as inputs to a reinforcement learning model to train a machine learning agent;
analyzing a set of performed actions performed by the trained machine learning agent to determine a measure of failure of the training of the machine learning agent, wherein the analyzing includes analyzing a label identifying an action of the set of performed actions as a positive action or a negative action;
based on the measure of failure reaching a threshold, pausing the machine learning agent and requesting a second set of example actions from the one or more input devices;
using the second set of example actions in addition to the first set of example actions to estimate a new reward function; and
using the new reward function, the first set of example actions, and the second set of example actions as additional inputs to the reinforcement learning model to train the machine learning agent.
|