| CPC G06N 20/20 (2019.01) [G06F 16/35 (2019.01); G06F 16/906 (2019.01)] | 15 Claims |
|
1. A method for identifying subpopulations, comprising:
receiving, with at least one processor, interaction data associated with a plurality of interactions from a population of individuals, the interaction data for each individual comprising a plurality of features, the plurality of features comprising a plurality of fields each associated with at least one of payment transaction data associated with a plurality of payment transactions, spendographic data determined based on the payment transaction data, or demographic data associated with a respective individual of the population of individuals;
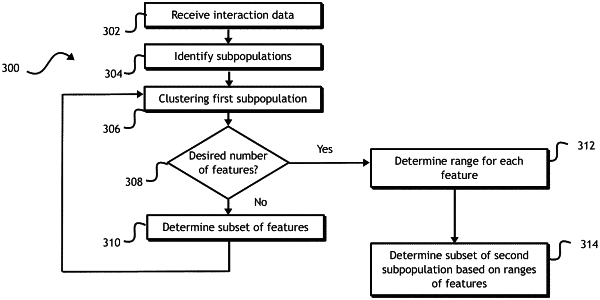
identifying, with at least one processor, a first subpopulation of the population based on at least one feature of respective interaction data of each respective individual in the first subpopulation, wherein a second subpopulation of the population comprises all individuals of the population other than the first subpopulation;
after identifying the first subpopulation, clustering, with at least one processor, the first subpopulation into a first plurality of clusters based on the plurality of features;
determining, with at least one processor, a first subset of the plurality of features based on the first plurality of clusters, wherein determining the first subset of the plurality of features comprises determining the first subset of the plurality of features based on the first plurality of clusters using at least one of a tree classifier or a random forest tree classifier;
clustering, with at least one processor, the first subpopulation into a second plurality of clusters based on the first subset of the plurality of features;
after clustering the first subpopulation into the second plurality of clusters, determining, with at least one processor, a number of features of a second subset of the plurality of features is outside a desired range, wherein determining number of features of the second subset of the plurality of features is outside the desired range comprises determining a variance explained by each feature of the second subset of the plurality of features does not exceed a threshold;
determining, with at least one processor, a further subset of the plurality of features based on the second plurality of clusters;
clustering, with at least one processor, the first subpopulation into a further plurality of clusters based on the further subset of the plurality of features;
repeating, with at least one processor, determining the further subset of the plurality of features and clustering the first subpopulation into the further plurality of clusters until a number of features of the further subset of the plurality of features is within the desired range, wherein determining the number of features of the further subset of the plurality of features is within the desired range comprises determining a variance explained by each feature of the further subset of the plurality of features exceeds the threshold;
replacing, with at least one processor, the second subset of the plurality of features with the further subset of the plurality of features and the second plurality of clusters with the further plurality of clusters;
after determining the number of features of the further subset of the plurality of features is within the desired range and replacing the second subset of the plurality of features with the further subset of the plurality of features and the second plurality of clusters with the further plurality of clusters, determining, with at least one processor, a range for each feature of a second subset of the plurality of features based on the second plurality of clusters;
after determining the range for each feature of the second subset of the plurality of features based on the second plurality of clusters of the first subpopulation, determining, with at least one processor, a subset of the second subpopulation based on respective interaction data for each respective individual of the subset of the second subpopulation and the range for each respective feature of the second subset of the plurality of features, the subset of the second subpopulation comprising a target subpopulation; and
after determining the target subpopulation, communicating, with at least one processor, at least one communication based on the target subpopulation.
|